 ```html HTML icon=code-xml expandable theme={"system"}
```html HTML icon=code-xml expandable theme={"system"}
Test PDF file content
 ```html HTML icon=code-xml theme={"system"}
```html HTML icon=code-xml theme={"system"}
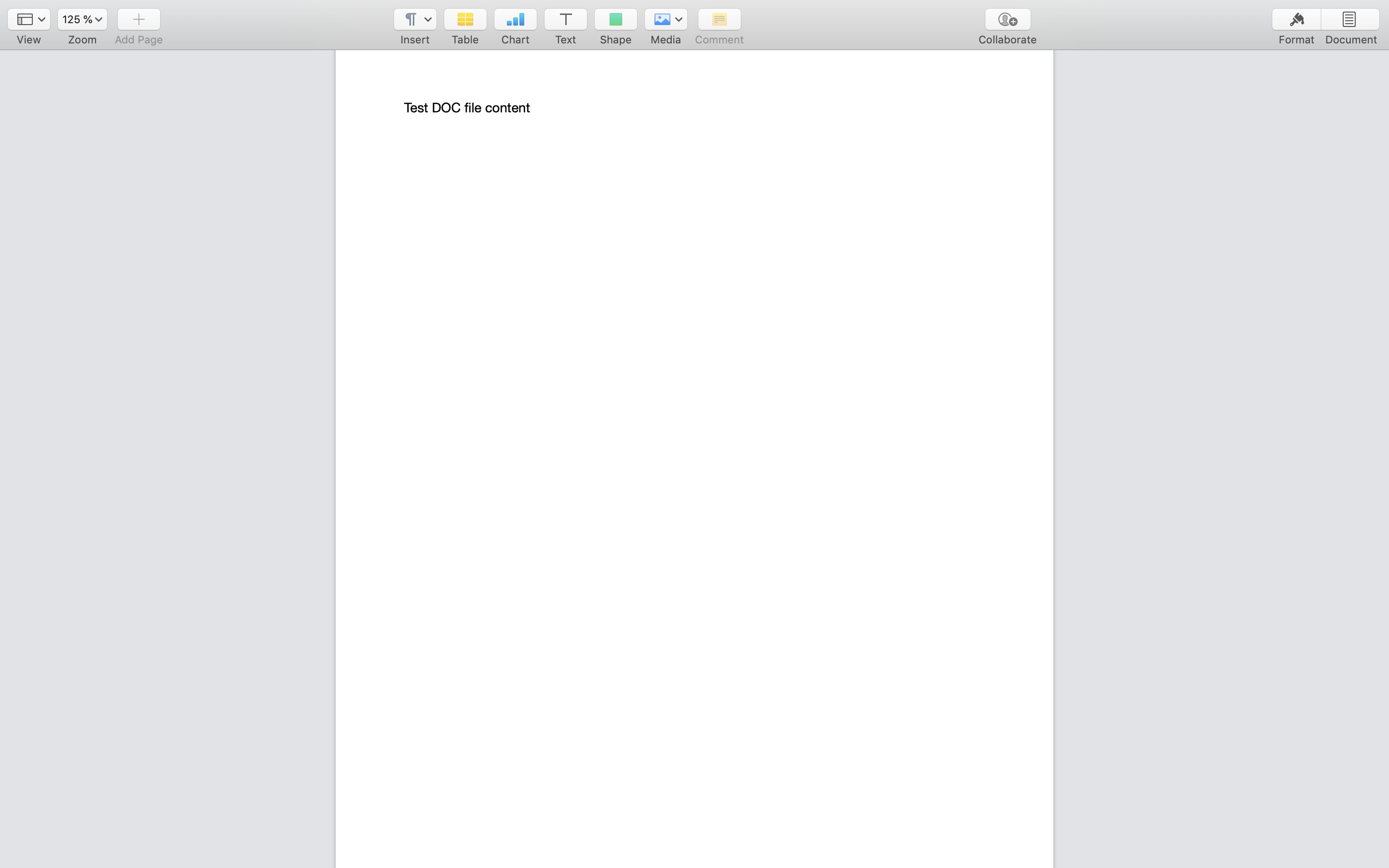
Test DOC file content
``` ### OpenDocument text documents * Associated extension: `.odt` * `fileTypesToMatch`: `odt` ### Microsoft Excel spreadsheets * Associated extensions: `.xls`, `.xlsx` * `fileTypesToMatch`: `xls` For example, in this `.xls` file, Tika exposes the following HTML, which the crawler then passes to its `recordExtractor`.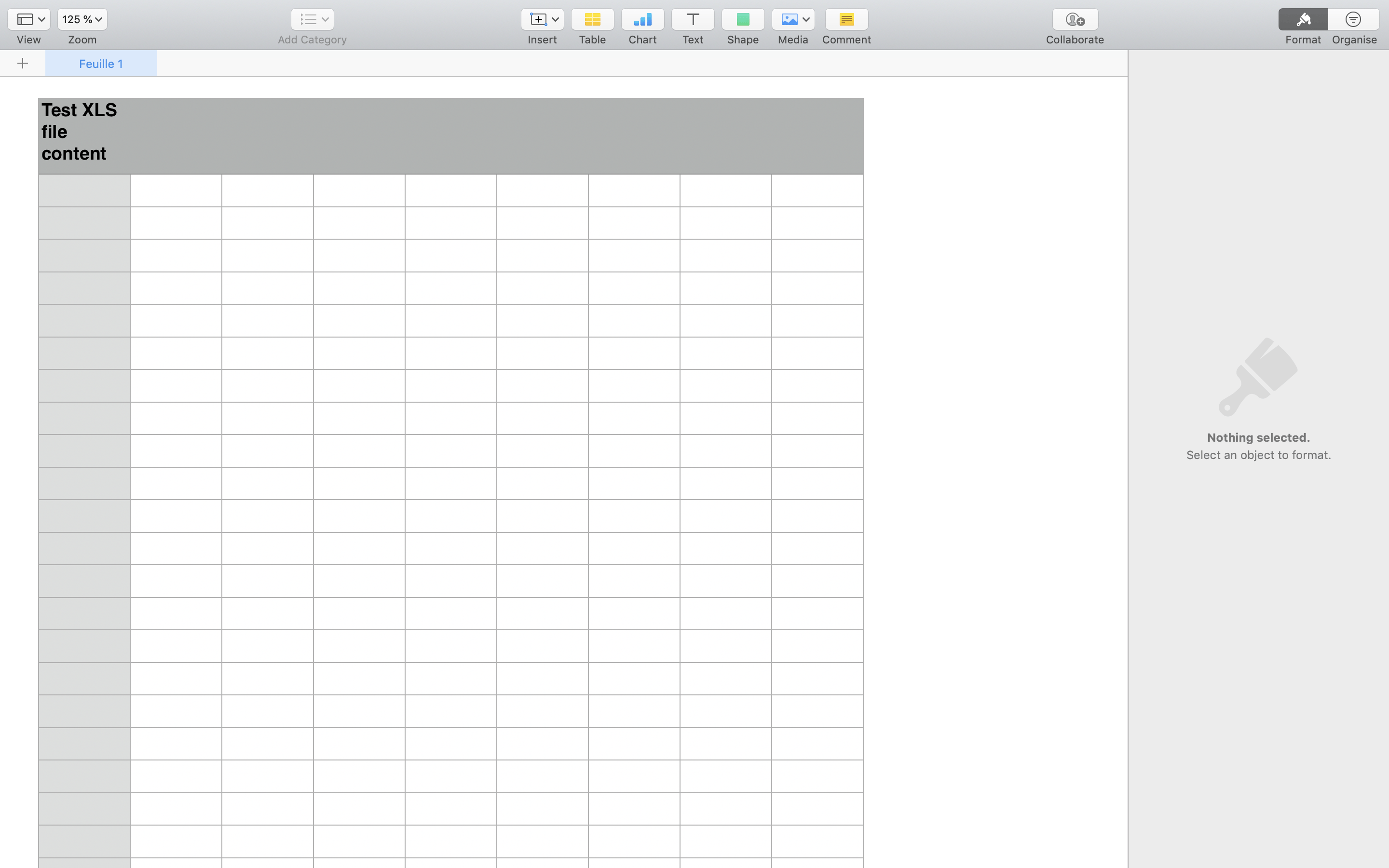 ```html HTML icon=code-xml theme={"system"}
```html HTML icon=code-xml theme={"system"}
| Test XLS file content |
 ```html HTML icon=code-xml theme={"system"}
```html HTML icon=code-xml theme={"system"}
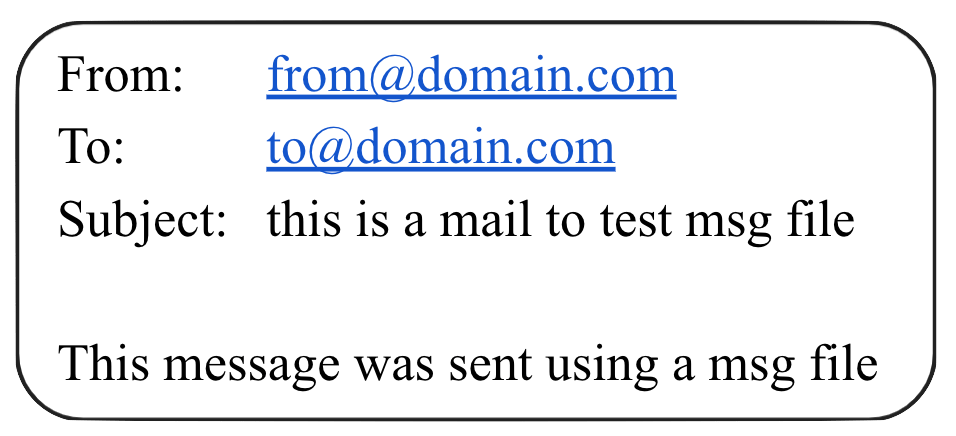 ```html HTML icon=code-xml expandable theme={"system"}
```html HTML icon=code-xml expandable theme={"system"}