Manage environments
If you have several environments, such as development, staging, and production, you can choose:- Use one index for each environment in the same Algolia application.
- Use one Algolia application for each environment.
You can use different datasets in environments other than production.
For example, index a small subset of your production data to reduce indexing operations.
One index for each environment in the same Algolia application
If you’re using a single Algolia , you can separate your production from your development and testing environments by creating separate indices. To distinguish the different environments, make sure to name your indices consistently, for example, by using prefixes or suffixes:dev_index, staging_index, prod_index.
Control access to your indices
Indices on the same Algolia application share the same . To control access to the index, create an Algolia user for each environment with different search and admin API keys.To create a dedicated user per environment, you need the Team Advanced Permissions feature.
Team Advanced Permissions is available as part of the Enterprise add-on to your pricing plan.
- Sign in to the Algolia dashboard.
- On the left sidebar, select Settings Settings.
- In the Team and Access section, click Team.
- Click Add Team Member and select the application to which you want to grant access.
-
Select the Index restrictions option and add the indices to which you want to grant access.
Use
"*"(asterisk) as wildcards, for example,dev_*,staging_*to grant access to all indices with a common prefix.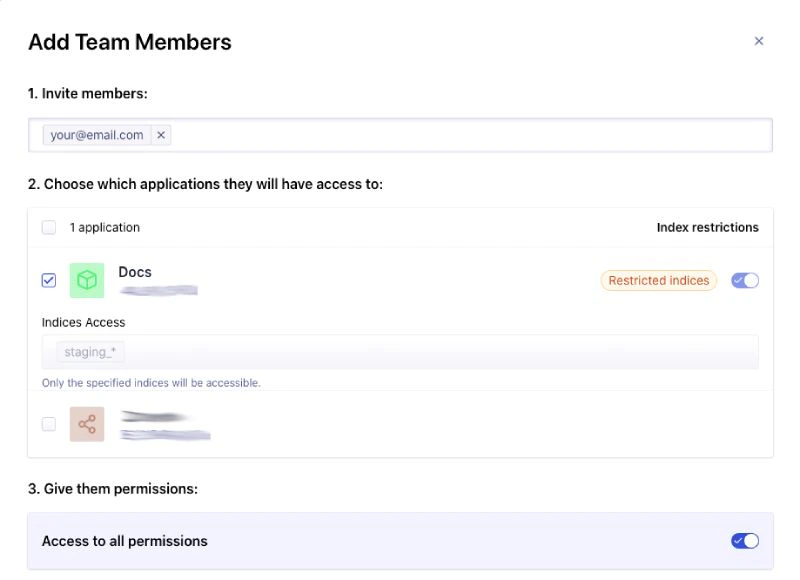
Separate Algolia applications for each environment
If you need complete isolation between your development, staging, and production environments, create an Algolia application for each. Separate Algolia applications each have their own pricing plan. Create new Algolia applications on the Applications page in the Algolia dashboard.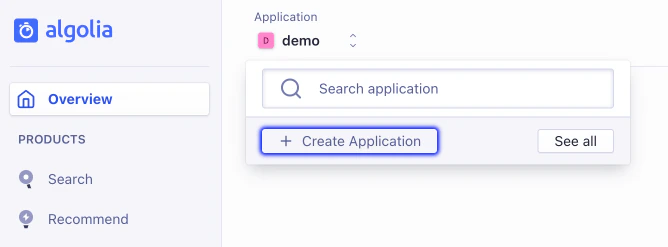
A dedicated cluster of servers is available as part of the Enterprise add-on to your pricing plan.
Manage your Algolia applications
Manage your Algolia applications from the dashboard. For example, to delete an unwanted Algolia application:- Go to the Applications page in the Algolia dashboard.
- Click Application actions and select Delete. If you don’t own this application, select Leave instead.
- Confirm your request.
There’s no API for programmatic application management.