Monitoring tool
The Monitoring tool lets you inspect your crawled URLs by status. Select a status to review the URLs associated with that status and further details about the processed URL. For more information, see Crawler error messagesURL inspector
The URL inspector shows details about the latest crawl for a selected URL, such as the time it took to process the URL, links to and from this URL, or extracted . You can search for individual URLs or filter by crawl status. If you click a link you can perform these actions with the selected URL:- Recrawl URL. This can be useful to check if a network error was only temporary, or if you’ve changed your crawler configuration and want to see the effect of your changes.
- Test URL. This opens the Editor page with the URL selected in the URL Tester.
URL Tester
The URL Tester lets you test your crawler’s configuration on one URL without crawling your entire site. This is helpful when updating your crawler’s configuration or when troubleshooting issues. To test a URL:- Open the Editor page in the Crawler dashboard. The URL Tester is on the right side of the screen.
- Enter the URL you want to test. The URL tester doesn’t follow redirects:
https://example.com/path/page/isn’t the same ashttps://example.com/path/page, even though it might work in your browser because of redirects. - Click Run Test.
| Tab | Description | Troubleshooting |
|---|---|---|
| All | All messages from all categories | Troubleshoot by crawl status |
| HTTP | The HTTP response sent back by your site’s server | Resolve any HTTP status errors |
| Logs | Issues reported by an action’s recordExtractor function | Review the logs for any issues reported by a recordExtractor. |
| Errors | Issues reported by the Crawler | Check the error message |
| Records | Records extracted from the URL | Check if all the records and attributes you expect are present |
| Links | Links on the page that match your configuration settings | Check that you recognize all the link paths you specified in the configuration |
| External Data | Any external data used to enrich this URL | Check if the external data that you specified is present in your records |
| HTML | The HTML source of the URL and a preview of the rendered page | Change your record extractor without leaving the URL Tester |
Path Explorer
The Path Explorer helps you find issues when crawling your site’s different sections (paths) and URLs. It shows:- How many URLs were crawled
- How much bandwidth was used when crawling these URLs
- How many records were extracted
Data Analysis
Consistent data is essential for a great search. The data analysis tool generates a report with the number of records that have data consistency issues. For example, if some of your records miss an attribute used for ranking, or use a different data type for this attribute, these records rank lower or won’t even appear in the search results.Find and fix bugs with the Data Analysis tool
When you have data inconsistencies, it can be difficult to track down what’s going on. The Data Analysis tool helps you find and fix the following kinds of issues:- Missing attributes
- Empty arrays
- Attributes with different types across records
- Arrays with elements of different types, even within a single record
- Suspicious objects that could be of another type, like a string used as an object
- Article publication date so the most recent articles appear first.
- Recently updated status so you can promote articles with fresh information.
JavaScript
date and subtitle attributes:
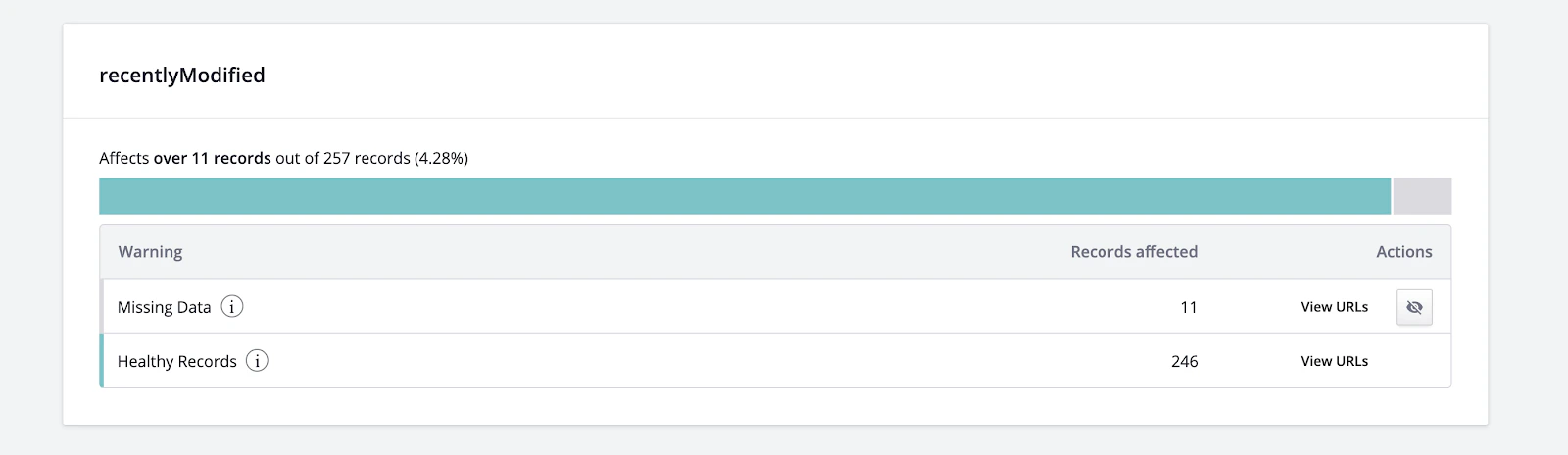
recentlyModified attribute.
This suggests that there’s an issue with the code used to extract this piece of data.
Click View URLs to investigate the warning further.
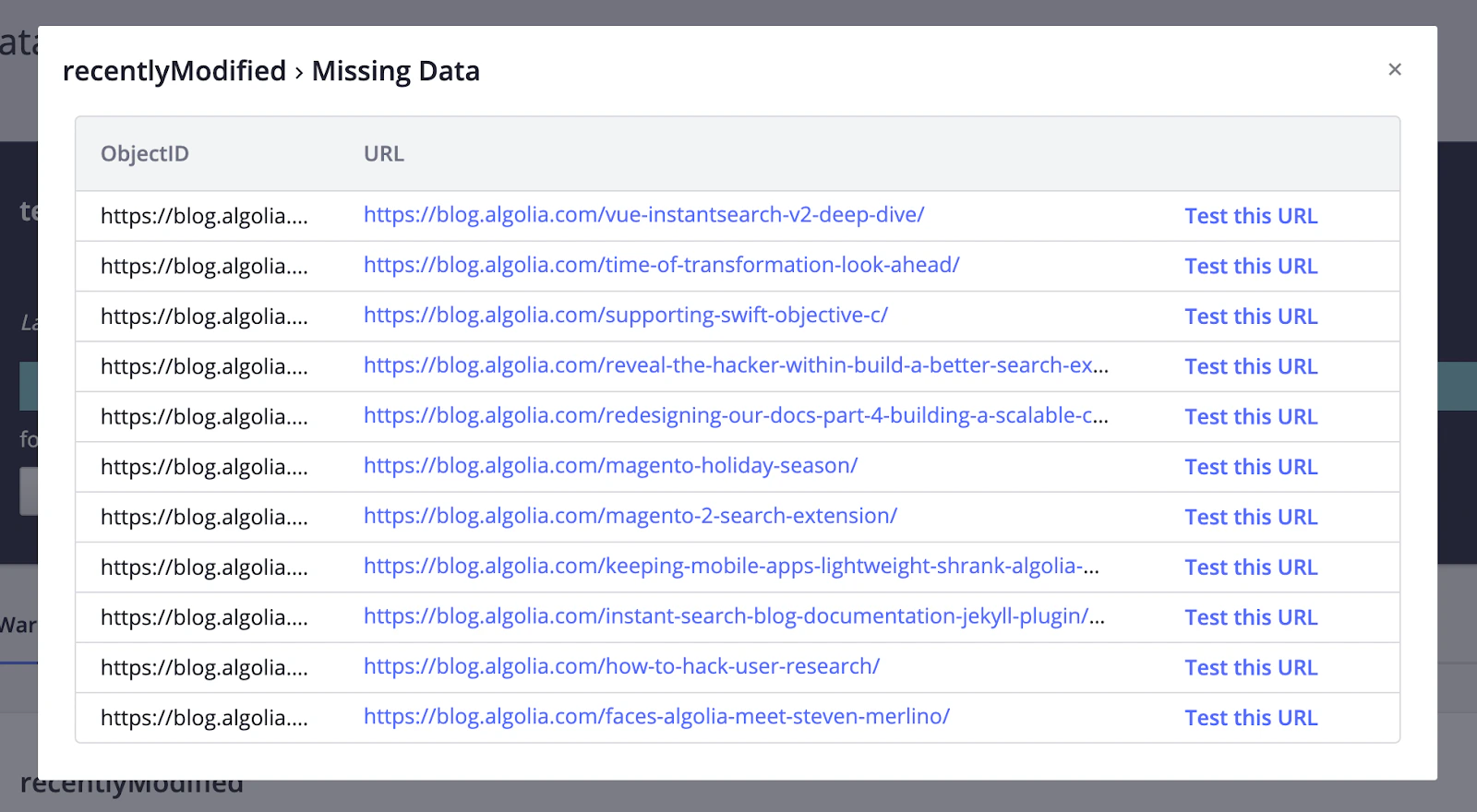

JavaScript
recentlyModified attribute when publishedAt is equal to modifiedAt.
In this situation, it should be false, because the article wasn’t modified.
You can update the code and immediately test the changes on the problematic URL by clicking Run Test.
JavaScript
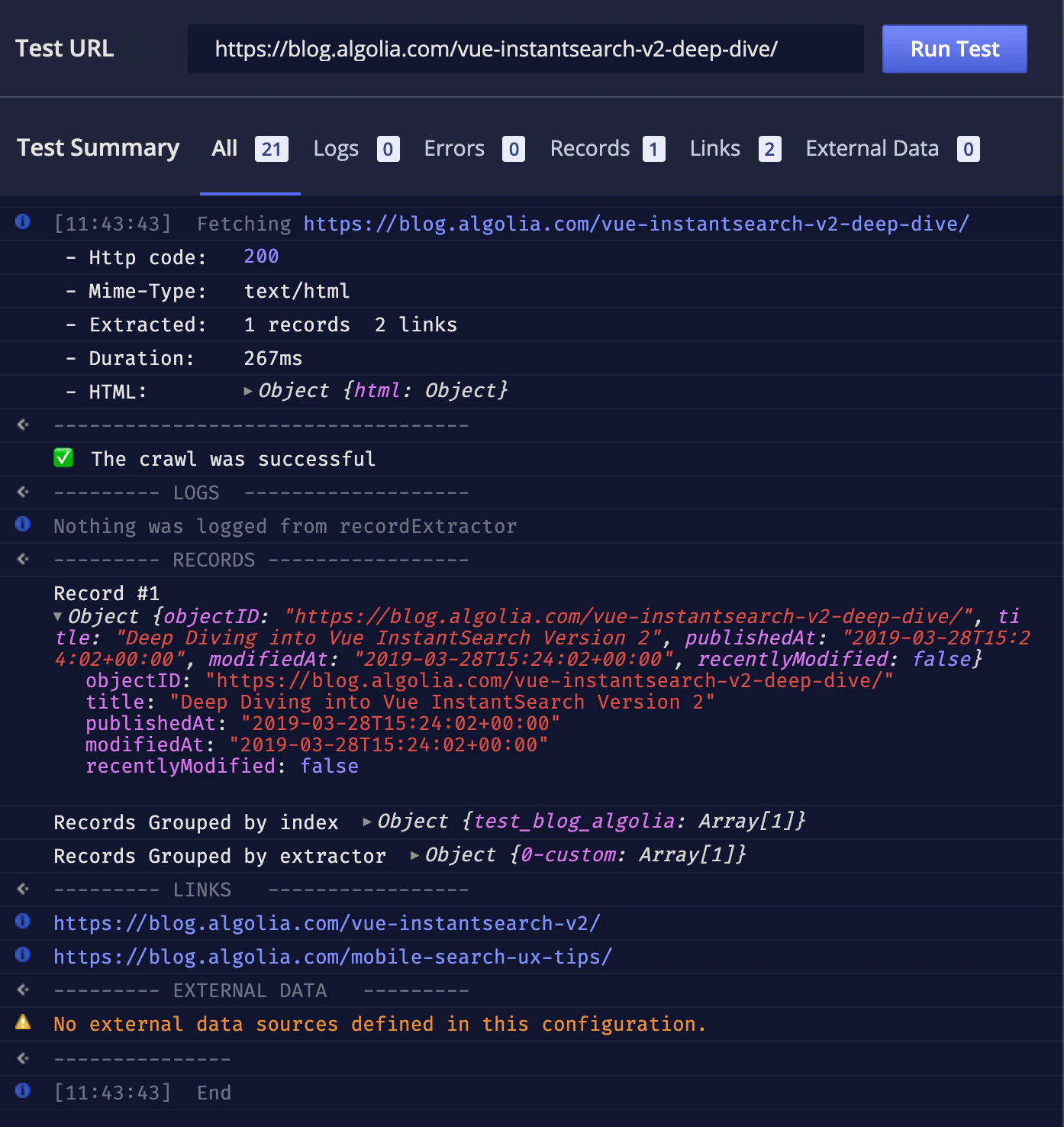
recentlyModified attribute is now present even when an article wasn’t modified.
You can now save the configuration and start a new crawl.
When the crawl is complete, you can run another analysis to validate that the configuration is correct: it shows no warnings.