Large language models (LLMs) are a vital part of the broader search pipeline. But when selecting an LLM for your search application, you need to look beyond generic performance and find a model that aligns with your specific use case. In this article, we’ll take a look at benchmarking methodologies and review the performance results of Algolia’s latest models.
LLM embeddings for search
Search is more than just an LLM. Search includes personalization, ranking, keyword fusion, and more. But LLMs play an important part in deploying search efficiently. So, where do LLMs fit in Algolia’s NeuralSearch solution?
NeuralSearch is an end-to-end search experience empowered by LLMs:
.avif)
LLMs power NeuralSearch, Algolia’s end-to-end search experience. These generic models are trained on publicly available datasets. We architecturally optimize and quantize these models to reduce latency and improve retrieval performance.
But how do you know what attributes are needed to compute text-to-vector representations? A key challenge is ensuring the embeddings sit close to each other in the embedding space. Algolia solves this problem with a module that computes the optimal weights to aggregate all the attribute embeddings and match them as close as possible to the associated query.
Furthermore, we have a hash hash model that compresses the dense embedding vectors, which ensures improved latency during the retrieval process. We also blend keyword with neural results, which creates a vector search-as-you-type. We call this hybrid search. The entire system is accelerated via CDN caching, achieving an 8x increase in computational speed.
NeuralSearch is all of these components put together, powered by the trained LLM. The LLM is a very important part of it, but all the other critical components are what makes it work for search.
Sentence-BERT for efficient embeddings
To efficiently generate sentence embeddings, we use Sentence-BERT, a neural network architecture built on encoder-only BERT models. These models are trained with publicly available online content and have the emergent capability to predict missing information and learn generic semantic relationships.
If we put a little bit of nonlinearity at the end of the BERT, which is like adding a feedforward neural network, and then train it to learn similarities between two sentences from end-to-end, we get Sentence-BERT.

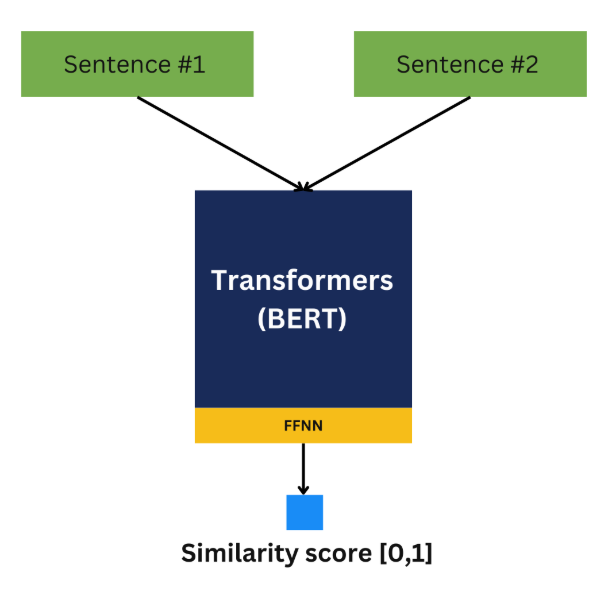
Semantic search maps each sentence to a vector space such that similar ones are closer to each other
Sentence-BERT generates sentence embeddings that sit either close to each other in a specific vector space if they are relevant or far away from each other if they are irrelevant. Because they are encoder only, they are smaller, more efficient, lower latency, and more feasible for deployment.
Though decoder-only models such as ChatGPT can also give extremely accurate results, due to their sheer size, costs, and latency, they are impractical for search applications. This is why Algolia uses an encoder-only model like Sentence-BERT.
Benchmarking LLMs for search
Evaluating LLMs in the context of the specific problem is crucial. Unbiased research and public benchmarks offer a standardized way to compare model performance across tasks like retrieval, classification, and semantic similarity.
Public LLM Benchmarks
For search purposes, we will concentrate on retrieval tasks. Examining four open benchmarks reveals that each includes:
- Various tasks, including retrieval
- Both multilingual and English
- Many different data sets within the benchmark
- A standard way to compute all the metrics associated with the tasks.
|
MTEB
|
BEIR
|
STS-B
|
TREC/MS MARCO
|
|
Diverse (retrieval, STS, etc.)
|
Retrieval-focused
|
STS-focused
|
Retrieval-specific
|
|
Multilingual (>50 languages)
|
Predominantly English
|
Predominantly English
|
Predominantly English
|
|
100+ datasets
|
~20 datasets
|
Few datasets
|
Medium (domain-specific)
|
|
Designed for embeddings
|
Retrieval embeddings
|
Pairwise similarity
|
Retrieval embeddings
|
|
Unified framework
|
Fragmented setup
|
Task-specific only
|
Retrieval pipelines needed
|
Two important observations over time are:
- As models evolve, scientists overfit leaderboards based on signals they get from evaluations or test sets. That's why we have internal benchmarks that take into consideration the context of the problem.
- These benchmarks are generic. They range from answering questions about history, medical medicine, and legal documents which may have nothing to do with e-commerce or retail.
Algolia LLMs and Benchmarks
Algolia has internal benchmarks that more accurately reflect data distribution for specific use cases. These private ecommerce datasets were created in collaboration with customers that were interested in evaluating their performance. The datasets tell us how users reacted to products, so that we can learn how to increase conversions.
Our models can work for any vertical, but will work best for customers in a range of specific verticals, such as fashion and apparel or electronics and technology.
Algolia still uses MTEB and public e-commerce datasets to make sure we are not diverging from earlier learnings. We try to keep early learnings intact as much as possible when we fine tune these models.
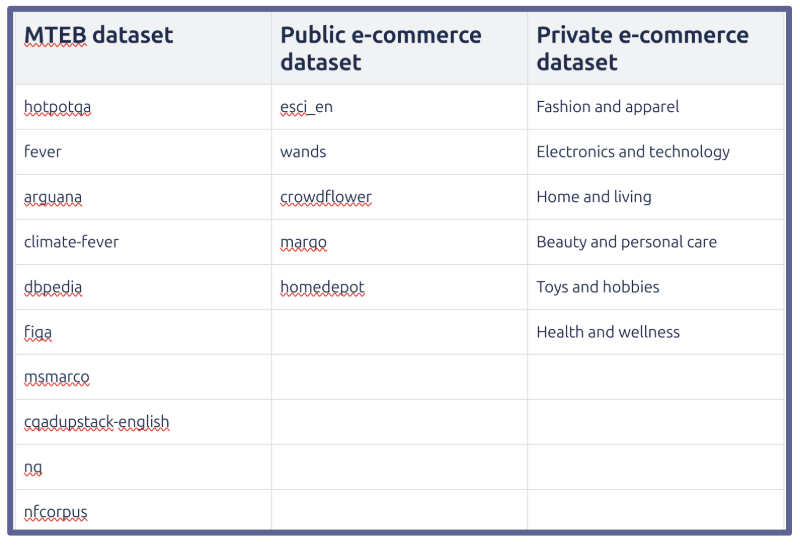
Algolia internal e-commerce benchmark includes 9 private datasets in collaboration with our customers
Algolia builds and fine-tunes LLMs to deliver the ultimate e-commerce search experience with everything happening in-house using our automated pipelines. Our most recent models are:
Algolia-Large-EN-Generic-v2410
|
Base:
|
gte-large
|
|
Datasets:
|
Public e-comm (+Syn.)
|
|
Dimension:
|
1024
|
Algolia-Large-Multilang-Generic-v2410
|
Base:
|
Solon-embeddings-large-0.1
|
|
Datasets:
|
Public e-comm (+Syn.)
|
|
Dimension:
|
1024
|
Note: Algolia is releasing version 2410 under permissive MIT license so that anyone can test these models capabilities and give us feedback.
Algolia builds embedding models that are approximately 500M parameters to ensure desired latency and cost efficiency. Each LLM is architecturally optimized and quantized to ensure even lower latency.
Both of the models were trained on publicly available ecommerce datasets and synthetically-generated performance triples. This means we embed the corpus and all the queries from public ecommerce and iteratively generate new pairs of queries and retrieved results.
Generating similar queries expressed in different ways builds the synthetic data set and incrementally improves all of these models in terms of latency.
Algolia Inference API
We use Algolia Inference API when we deploy our models.
- Currently Algolia inference API supports up to 20,000 query per second per region.
- P50 and P90 latency ranges from around 4 to 7 milliseconds respectively. The CDN caching and smart distribution is what brings us that latency capability.
- We have lightning fast inference. This is extremely important to search because speed equals more conversions.
Neural vs. keyword latency
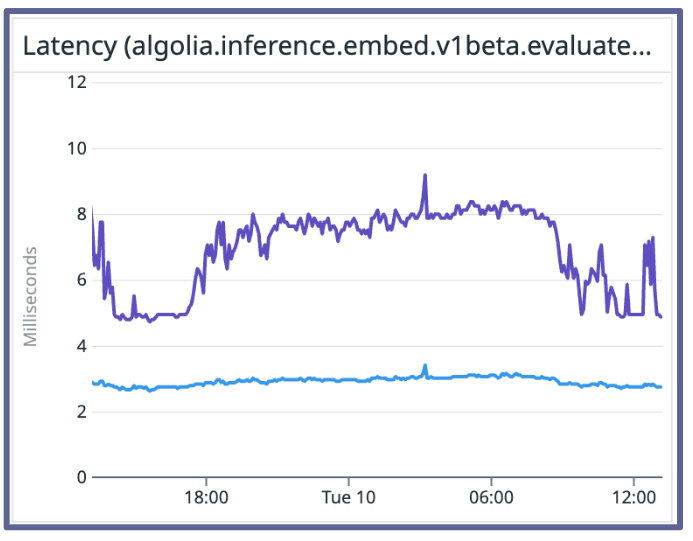
Benchmark results
Benchmark (Private Multilang)
Algolia LLMs ranked in the top 10 for Algolia private multilingual datasets and highest with a permissive license.
In the private multilingual benchmarks, two of our models sit in the top 15. OpenAI, Google, and Jina lead the pack, with Algolia and Cohere following closely. There's a clear jump between the top three and the others. Algolia continues to review at our benchmark every month and chase the leaderboard.
Benchmark (Private English)
.avif)
Algolia LLMs are highly ranked in the top 15 for Algolia private English datasets, the performance difference is marginal here.
In the private English benchmarks, performance differences are marginal. Two of Algolia’s models are in the top 15, with the English large version placing seventh. In English private, we don't see similar banding as in multilingual capability. There is little difference between each of the models with just marginally decreasing performance.
Benchmark (Public eCommerce)

Algolia-large-EN-generic LLM ranked second for public e-commerce datasets in English overall, the performance difference is quite small.
If you look at publicly available ecommerce data sets, Algolia’s models perform pretty well. Our English version is in second place and our multilingual version is in 12th place. Still, the difference is small mostly due to the fact that people train on these publicly available models.
Benchmark (MTEB)
.avif)
Algolia-large-EN-generic LLM ranked in the top 15, and it is interesting to see there are missing models that perform highly on private benchmarks.
For the MTEB benchmark Algolia’s English is at eleven and although it is not ranked in this chart, multilingual placed 21st.
Notably, models that perform well in internal ecommerce benchmarks often rank lower here, reinforcing the need for internal evaluation that reflects your data distribution. The MTEB benchmark is not enough to indicate which model performs better.
In summary, looking at Algolia’s v2410 models both English and multilingual versions scored high in public and private ecommerce ranking but were lower in MTEB ranking benchmarks.
Algolia LLM Benchmark - v2410

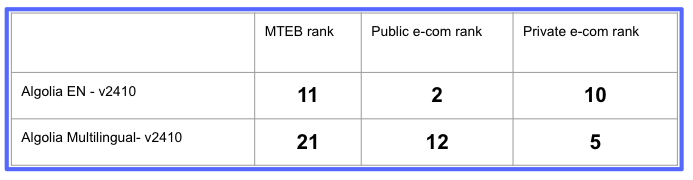
Algolia-large-EN-generic-v2410 models perform superior across public and private benchmarks.
Algolia Next Generation LLM
.jpg)
 Algolia’s next generation v2412 LLMs will soon be available for all of our NeuralSearch customers.
Algolia’s next generation v2412 LLMs will soon be available for all of our NeuralSearch customers.
The key takeaways are:
- Evaluating LLMs in the context of specific problems is critical for success.
- New LLMs are added to our benchmarks typically within 24 hours.
- Algolia builds and fine-tunes LLMs using fully-automated pipelines.
- Algolia v2410 models (now available under MIT license) are state-of-the-art for their size and use cases.
Algolia is actively developing next-generation LLMs (v2412), which will soon be available to all NeuralSearch customers.
Visit Algolia’s company space on HuggingFace to try out our models for yourself. And don't forget to leave feedback.
To learn more, watch my DevBit presentation and Q&A session on this topic: Uncover the right LLM for your use-case
 AI Search
Les résultats que les utilisateurs veulent voir
AI Search
Les résultats que les utilisateurs veulent voir AI Browse
Pages de catégories et de collections construites par l'IA
AI Browse
Pages de catégories et de collections construites par l'IA AI Recommendations
Suggestions à tout moment du parcours utilisateur
AI Recommendations
Suggestions à tout moment du parcours utilisateur Merchandising Studio
Expériences client améliorées grâce aux données, sans code
Merchandising Studio
Expériences client améliorées grâce aux données, sans code Merchandising Studio
Expériences client améliorées grâce aux données, sans code
Merchandising Studio
Expériences client améliorées grâce aux données, sans code Analytics
Toutes vos informations dans un seul tableau de bord
Analytics
Toutes vos informations dans un seul tableau de bord Composants UI
Composants pré-construits pour des parcours personnalisés
Composants UI
Composants pré-construits pour des parcours personnalisés






%20(2).svg)
