We invited our friends at Starschema to write about an example of using Algolia in combination with Rust. They came up with a very unique use case that we hope will inspire you to use Algolia in different ways. Get a beverage and enjoy this article by Senior Developer Gyula László!
The data-driven nature of most contemporary software means that debugging also happens on two different levels: debugging your code and debugging the data as used by your code. While modern IDEs offer a plethora of code debugging tools, they generally contain only very basic data-debugging facilities (the most commonly used is displaying the contents of variables from the current scope).
IDEs cannot offer higher-level data-debugging services, because they do not know anything about the higher-level structure of your data.
Example scenario
The example we’ll be using envisions a small game engine dev team working as part of a larger team developing content for the game engine (in Rust). The challenge is to debug cases coming from QA.
If we assume that unit testing catches the most straightforward bugs (like typos, basic logic problems, etc), these QA issues generally stem from the fact that the data created by the content teams are vastly different and much more complex than scenarios tested by the unit tests. Debugging generally involves large amounts of logs and post-run collation of data created during the run.
One solution to ease this pain as used by CD Project Red, and explained in the ‘The Witcher 3: Optimizing Content Pipelines for Open-World Games’ GDC talk, is to have a searchable database for every entity used during build time. This is a great solution for product-wide issues (and was generally aimed at content-developers), but may not be the best fit for our “small team focused on core code development” scenario:
- They require cooperation from all other teams (and product-wide build system modifications)
- The DB requires maintenance
- “All of the data” is generally overkill for these debug sessions (sorting through will eat up more time)
- Debugging by modifying the data for individual test runs is not supported (as the whole DB assumes a single, consistent set of input data)
What do we want?
The idea of having a database feels good, but we have some more requirements:
- We want to build the database from runtime data (not build time)
- We want multiple, parallel databases (as the team can be working on a number of issues)
- Entity data is freeform — as we may change structure during debugging, we do not want to specify schemas in advance
- We do not want to waste time maintaining the database
- We want fast search capabilities
*
* Some notes on “fast search”: one of the most common tasks of tracking things down is to match addresses or ids across multiple entities, and we do not want to run multiple SQL queries per entity type, as it is slow and demotivating to copy-paste the same id to 9 different queries, and to then copy-paste the results into a single text editor window for checking.
Algolia
When looking at Algolia, we see that it meets our DB criteria:
- Support for multiple databases
- Data is freeform
- No maintenance needed
- Has really good search capabilities
- Can build simple, custom UIs for searching
With this in mind we can create a list of what we need to code to get data to Algolia:
- We want an easy way to mark-up data for Algolia serialization (we can use JSON serialization for this purpose)
- Create a library that can send serialized data to Algolia (preferably with a single, simple call)
- Enable easy configuration of the library
Sending data to Algolia
Where do we send it and how?
Algolia does provide documentation on how to use the REST API, however, none of the currently available libraries work for Rust (no C or C++ version to wrap either) so we’ll have to make use of the API clients automation repository which is used to generate the clients themselves.
As a baseline, let’s look at the JavaScript client example provided:
// for the default version
import { algoliasearch } from 'algoliasearch';
// you can also import the lite version, with search only methods
// import { liteClient } from 'algoliasearch/lite';
const client = algoliasearch('<YOUR_APP_ID>', '<YOUR_API_KEY>');
// The records retrieved by any of your data sources
const recordsFromDataSource = [
{ name: 'Tom Cruise' },
{ name: 'Scarlett Johansson' },
];
// Here we construct the request to be sent to Algolia with the `batch` method
const requests: BatchOperation[] = recordsFromDataSource.map((record) => {
return {
// `batch` allows you to do many Algolia operations, but here we want to index our record.
action: 'addObject',
body: record,
};
});
const { taskID } = await client.batch({
indexName: '<YOUR_INDEX_NAME>',
batchWriteParams: {
requests,
},
});
// Wait for indexing to be finished
await client.waitForTask({ indexName: '<YOUR_INDEX_NAME>', taskID });
console.log('Ready to search!');
So the process looks fairly straightforward:
- Provide authentication for Algolia using the
APP_ID and API_KEY
- Pack up the data that we’d like to send (see this spec partial)
- Send the request to Algolia
- We can skip waiting for indexing to be done (as we are in core code we’d like to avoid long waits)
One downside of using the REST API directly is that Algolia does not offer an SLA if you are not using an official API Client.
Authentication
To figure out how authentication is handled let’s trace the algoliasearch(...) constructor call:
- In
clients/algoliasearch-client-javascript/packages/algoliasearch/builds/browser.ts we see that the default auth option is WithinQueryParameters and is hard-coded — we’ll use this
- Later we see that
createSearchClient() in clients/algoliasearch-client-javascript/packages/client-search/src/searchClient.ts is what does the actual job of building most of the algoliaclient object (including the parts we care about)
- This creates the authentication using
createAuth() in clients/algoliasearch-client-javascript/packages/client-common/src/createAuth.ts:
const credentials = {
'x-algolia-api-key': apiKey,
'x-algolia-application-id': appId,
};
return {
headers(): Headers {
return authMode === 'WithinHeaders' ? credentials : {};
},
queryParameters(): QueryParameters {
return authMode === 'WithinQueryParameters' ? credentials : {};
},
};
This clearly shows that we’ll have to add x-algolia-api-key and x-algolia-application-id to the query parameters for authentication.
The hosts
The host list to target is coming from the getDefaultHosts() function in searchClient.ts, and we see that it has read, write, and readwrite hosts:
function getDefaultHosts(appId: string): Host[] {
return (
[
{
url: `${appId}-dsn.algolia.net`,
accept: 'read',
protocol: 'https',
},
{
url: `${appId}.algolia.net`,
accept: 'write',
protocol: 'https',
},
] as Host[]
).concat(
shuffle([
{
url: `${appId}-1.algolianet.com`,
accept: 'readWrite',
protocol: 'https',
},
{
url: `${appId}-2.algolianet.com`,
accept: 'readWrite',
protocol: 'https',
},
{
url: `${appId}-3.algolianet.com`,
accept: 'readWrite',
protocol: 'https',
},
])
);
}
When checking the Transporter request() method, we can see that the read hosts are used for GET requests, and the write hosts are used for everything else.
As debugging is not mission critical, we’ll ignore the retry logic used by fully-fledged Algolia clients.
Creating the request
We can also see the request structure in searchClient.ts in .batch():
batch( { indexName, batchWriteParams }: ...) {
// ...
const requestPath = '/1/indexes/{indexName}/batch'.replace( '{indexName}', encodeURIComponent(indexName));
// ...
const headers: Headers = {};
const queryParameters: QueryParameters = {};
const request: Request = {
method: 'POST',
path: requestPath,
queryParameters,
headers,
data: batchWriteParams,
};
return transporter.request(request, requestOptions);
},
We can see that the path for the request will be /1/indexes/<INDEX>/batch, and the request looks like a standard POST request.
When tracing the createTransporter() call that initializes this we see that it adds a x-algolia-agent query parameter with Algolia for JavaScript (<VERSION>) value.
Reality check
With most of the details figured out, we want to create a quick test using the official Algolia Client SDK for Javascript to check if our assumptions about sending the data are correct. Using the Javascript Client Documentation, it’s easy to put together a simple HTML file that issues a batch upload request to Algolia:
<html>
<head>
<!-- load the Algolia JS library -->
<script src="<https://cdn.jsdelivr.net/npm/algoliasearch@4.5.1/dist/algoliasearch.umd.js>"></script>
</head>
<body>
<script>
// Connect and authenticate with your Algolia app
const client = algoliasearch('<APP CODE>', '<ADMIN API TOKEN>')
// Create a new index and add a record
const index = client.initIndex('<INDEX>')
const record = { objectID: 1, name: 'test_record' }
index.saveObject(record).wait()
// Search the index and print the results
index
.search('test_record')
.then(({ hits }) => console.log(hits[0]))
</script>
</body>
</html>

When running this in the browser we can see that it’s working, however, one difference we do see is that the x-algolia-api-key and x-algolia-application-id authentication keys are sent in headers, not in the query string. We’ll take note of this and use it instead of passing them as query parameters.
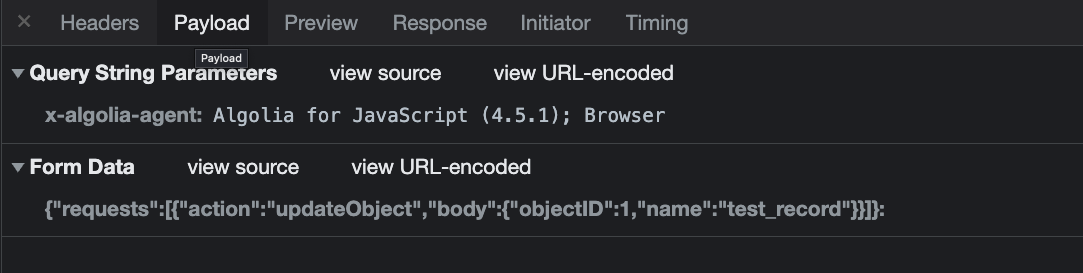
Another noteworthy bit is that the content-type of the request (despite having a JSON body) is application/x-www-form-urlencoded, not application/json (as one would guess by default) or text/plain (as the default content-type for the Transport). We take this as a hint to ignore content-type until we encounter problems.
Rust pieces
Marking the data for serialization
For handling the serialization we’re going to use the SerDe library.
SerDe is a framework for serializing and deserializing Rust data structures efficiently and generically.
This requires our structures to implement the Serialize trait (for most structures), and we only have to add a Serialize derive to their definition:
// A vector of 3 floats.
//
// The serialized form will look like `{"x":14.1,"y": 86.2,"z":14.3}`
#[derive(Serialize)]
struct Float3 {
x: f32,
y: f32,
z: f32,
}
One extra bit we saw in the sample code for the JavaScript Client SDK is the objectID field. To quote from the Algolia indexing documentation:
Every object (record) in an index eventually requires a unique ID, called the objectID. You can create the objectID yourself and send it when indexing. If you don’t send an objectID, Algolia generates it for you.
Whether sent or generated, once you add a record, it has a unique identifier called objectID.
For our application automatically generated unique ids would be ideal, but in reality, when sending data to the batch ingestion endpoint, all objects must have an objectID field and we can use SerDe to rename / transform / rearrange the fields.
// create a string key from the integer and add a prefix for unique id
fn particle_emitter_object_id<S>(id: &i32, s: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
s.serialize_str(format!("particle_emitter_{}", id))
}
// An example entity that a customized objectID for serialization
// The `rename_all` is used to transform underscored_name_format to camelCaseNameFormat
#[derive(Serialize, Deserialized, Debug)]
#[serde(rename_all = "camelCase")]
struct ParticleEmitterEntity {
// serialize this field as `objectID`, but transform it using the `particle_emitter_object_id` field
#[serde(rename = "objectID", serialize_with="particle_emitter_object_id")]
id: i32,
// nested objects are automatically serialzied
root_position : Float3,
// ...
}
Sending the data
We’ll use the Reqwest crate for our HTTP transport:
[dependencies]
reqwest = { version = "0.11", features = ["blocking", "json"] }
urlencoding = { version = "2.1" }
use urlencoding;
fn main() -> Result<(), Box<dyn std::error::Error>> {
// The credentials data
const APP_ID: &str = "<APP ID>";
const INDEX_NAME: &str = "<INDEX NAME>";
const API_KEY: &str = "<ADMIN API KEY>";
const ALGOLIA_AGENT: &str = "Algolia DataSender for Rust Dev (0.0.1)";
// build the URI for the batch
let host = format!("{}.algolia.net", APP_ID.to_lowercase());
// The index name can have non-url-friendly characters
let path = format!("/1/indexes/{}/batch", urlencoding::encode(INDEX_NAME));
let uri = format!("https://{}{}", host, path);
let uri_with_client = format!("{}?x-algolia-agent={}", uri, ALGOLIA_AGENT);
// The batch data needs to be in the proper batch request format.
// <SERIALIZATION CODE GOES HERE>
// let data = ....
// The `blocking` client waits for the request to complete
let client = reqwest::blocking::Client::new();
let res = client
.post(uri_with_client)
.header("x-algolia-api-key", API_KEY)
.header("x-algolia-application-id", APP_ID)
.body(data)
.send()?;
Ok(())
}
Pre-serialization
Since our goal is to be able to send arbitrary types to Algolia, we do not really care about the underlying objects, just the data. This helps because we would have a very hard time managing object lifetimes in Rust if we wanted to store actual objects in a buffer (and the type magic that we’d have to do would be dense and impenetrable). The solution is to serialize objects into a shared buffer as soon as they arrive, and work from the pre-serialized format when sending objects in batches.
Serde serialization is not suited to composing pre-serialized data, so we’ll do it the un-Rust way: we compose the data via string manipulation instead of type-safe serialization code.
[dependencies]
serde = { version = "1.0", features = ["derive"] }
serde_json = { version = "1.0" }
use serde::Serialize;
// ...
// The data we'll send for testing
#[derive(Serialize, Debug)]
struct Float3 {
#[serde(rename="objectID")]
object_id: String,
x: f32,
y: f32,
z: f32,
}
// RECREATE THE REQUESTS STRUCTURE
// -------------------------------
// {"requests":[{"action":"updateObject","body":{"objectID":1,"name":"test_record"}}]}
// convert a pre-serialized JSON object into a request object for a batch request
fn build_batch_request_entry(data: &String) -> String {
format!("{{\\\\"action\\\\":\\\\"updateObject\\\\",\\\\"body\\\\":{}}}", data)
}
// wrap the individual requests into a batch
fn wrap_batch_request_entry(rows: &Vec<String>) -> String {
format!("{{\\\\"requests\\\\":[{}]}}", rows.join(","))
}
// Create some raw data we'll send for testing
let raw_data = vec![
serde_json::to_string(&Float3 {
object_id: String::from("point1"),
x: 0.1,
y: 0.2,
z: 0.3,
})
.unwrap(),
serde_json::to_string(&Float3 {
object_id: String::from("point2"),
x: 1.1,
y: 1.2,
z: 1.3,
})
.unwrap(),
];
// transform the list of raw data objects to individual `updateObject` requests,
// then collect and wrap them in the `requests` array for the batch Algolia request
let data = wrap_batch_request_entry(&raw_data.iter().map(build_batch_request_entry).collect());
Using this pre-wrapped data we can combine them into a working example submitting data to Algolia indices which you can find in example1.rs.
Wrapping up into a neat API
Now that the transport and data encoding is ready, we can wrap this up into a neat API:
// Allows sending serializable data to Algolia indices
pub struct AlgoliaSender {
/// ...
}
impl AlgoliaSender {
// create a new sender with the given credentials and index
pub fn new(app_id: &str, api_key: &str, index_name: &str) -> Self { }
// adds a new serializable item to the list to be sent on the next send_items() call
pub fn add_item<T>(&mut self, v: &T) where T: Serialize {}
// Send the items to the default index
pub fn send_items(&mut self) {}
// Sends items to the ingestion endpoint in a batch job to a specified index
pub fn send_items_to_index(&mut self, index_name: &str) {}
}
Which then can be used like this:
// create a sender
let mut sender = AlgoliaSender::new(APP_ID, API_KEY, INDEX_NAME);
// add some items to send
sender.add_item(&Float3 {
object_id: String::from("point3"),
x: 0.1,
y: 0.2,
z: 0.3,
});
sender.add_item(&Float3 {
object_id: String::from("point4"),
x: 1.1,
y: 1.2,
z: 1.3,
});
// send the items in a request (so batch split points can be controlled)
sender.send_items();
For the full code of this step please see example2.rs.
Adding individual object ids
Since we do not really want to add objectID fields to our internal data structures, we have to add some extra logic to generate these for us.
First, let us create a generator for these IDs:
// Generates unique IDs to use as ObjectIds.
//
// This implementation combines a prefix with an incremental index.
pub struct IdGenerator {
prefix: String,
idx: i32,
}
impl IdGenerator {
// Creates a new IdGenerator with the given prefix
pub fn new(prefix: String) -> Self {
IdGenerator { prefix: prefix, idx: 0 }
}
// Creates a new IdGenerator with the current epoch time as prefix
pub fn new_from_time() -> Self {
let now = SystemTime::now();
let prefix = format!("{:?}", now.duration_since(std::time::UNIX_EPOCH).unwrap_or_default());
Self::new(prefix)
}
// Returns a new integer id and increments the internal counter
pub fn next_i32(&mut self) -> i32 {
let idx = self.idx;
self.idx += 1;
idx
}
// Returns a concatenated string id and increments the internal counter
pub fn next_string(&mut self) -> String {
let next_id = self.next_i32();
format!("{}_{}", self.prefix.as_str(), next_id)
}
}
Then we can do the ugly string manipulation of injecting a generated objectID into our already serialized objects. This assumes that everything we are sending is an object, not an array or a primitive value — with Algolia expecting objects this is just fine for us. We use filter_map() to skip entries that are too short (which would be most likely invalid JSON).
// converts a pre-serialized JSON object into a request object for a batch request using DANGEROUS STRING MAGIC
fn build_batch_request_entry(id: &String, data: &String) -> Option<String> {
if data.len() <= 2 {
return None;
}
// Skip the opening curly brace and inject our objectID into the already serialized object
let remaining_data:String = data.chars().skip(1).collect();
Some(format!("{{\\\\"action\\\\":\\\\"updateObject\\\\",\\\\"body\\\\":{{\\\\"objectID\\\\":\\\\"{}\\\\",{}}}", id, remaining_data))
}
// Wrap all pre-serialized data with an object id and the `updateObject` request, then collect into a batch request
let data = wrap_batch_request_entry(
&self
.data_buffer
.iter()
.filter_map(|entry: &String| -> Option<String> { build_batch_request_entry(&self.id_generator.next_string(), entry) })
.collect(),
);
The full code for this step is available in example3.rs.
Exposing to C / C++
Since our library is separated into two distinct parts: serializing objects to JSON and sending the data, we can actually expose our Rust library to C / C++ code for easy data ingestion from those languages. If they can provide JSON-serialized data then we can send it.
Our goal is to have an API with a constructor and destructor for the struct and functions that mimic the public API of the Rust side. The following is a first-draft, brute-force implementation of these functions:
[dependencies]
libc = "0.2"
// We need to support adding pre-serialized data directly
impl AlgoliaSender {
//...
// adds an already serialized value to be sent
pub fn add_raw_item(&mut self, data: &str) {
self.data_buffer.push(String::from(data));
}
// ...
}
// C API
// -----
// Constructor for the AlgoliaSender struct from C.
// Returns nullptr if any of the parameters are empty.
#[no_mangle]
pub unsafe extern "C" fn algolia_sender_new(app_id: *const libc::c_char, api_key: *const libc::c_char, index_name: *const libc::c_char) -> *mut AlgoliaSender {
// rustify all parameters
let app_id_str: &str = std::ffi::CStr::from_ptr(app_id).to_str().unwrap_or("");
let api_key_str: &str = std::ffi::CStr::from_ptr(api_key).to_str().unwrap_or("");
let index_name_str: &str = std::ffi::CStr::from_ptr(index_name).to_str().unwrap_or("");
// check these parameters
if app_id_str.is_empty() || api_key_str.is_empty() || index_name_str.is_empty() {
return std::ptr::null_mut();
}
// create a new sender and Box it, and use `Box::into_raw()` to get a pointer that outlives this function call
let struct_instance = AlgoliaSender::new(app_id_str, api_key_str, index_name_str);
let boxed = Box::new(struct_instance);
Box::into_raw(boxed)
}
// Destructor for the AlgoliaSender struct from C
#[no_mangle]
pub unsafe extern "C" fn algolia_sender_destroy(struct_instance: *mut AlgoliaSender) {
// let the Rust lifetime take over and destroy the instance after the function is done
Box::from_raw(struct_instance);
}
// Adds an item to be sent to the target sender
#[no_mangle]
pub unsafe extern "C" fn algolia_sender_add_item(a: *mut AlgoliaSender, data: *const libc::c_char) {
// convert data
let data_str = match std::ffi::CStr::from_ptr(data).to_str() {
Err(_) => return,
Ok(s) => String::from(s),
};
// attempt to add it
match a.as_mut() {
None => return,
Some(sender) => sender.add_raw_item(data_str),
};
}
// Trigger the sending of items
#[no_mangle]
pub unsafe extern "C" fn algolia_sender_send_items(a: *mut AlgoliaSender) {
// attempt to send the items
match a.as_mut() {
None => return,
Some(sender) => sender.send_items(),
};
}
The full source code for this step is available in example4.rs.
Sample use-case
Our example is a fairly simple one:
- The content team is creating a map by placing objects and by writing rules for procedural content generation
- We want to keep a searchable database of all objects (including procedural ones)
- We want to be able to find objects by any property and display the known properties of that object in the browser
- From the browser search, we want to be able to quickly go to that object in the internal editor tool for evaluation (using a link with a custom protocol)
The data structure that we’d like to send over looks like the following:
#[derive(Serialize)]
pub enum EntityCategory {
StaticEntity,
...
}
#[derive(Serialize)]
pub struct PlacedEntity {
// The root position of the object -- we'll use these coordinates to create the link to open the editor
root: Float3,
// we'll use this as an example of adding selectable categories to the search UI.
category: EntityCategory,
// other properties
// ...
}
The category enum is stored as an integer under the hood, but thankfully by default SerDe represents Enums as “externally tagged”, so they should arrive at Algolia as Strings instead of integers. We’ll use this category attribute to add a “category selector” on the UI.
To be able to keep track of both static and procedural objects, we can use the library to send object data to Algolia after object creation. For this example we assume that a ObjectContainer::place_entity() is used for placing a single object and ObjectContainer::placement_done() is called after a batch of objects are added.
// ...
impl ObjectContainer {
pub fn new() -> Self {
Self {
//...
algolia_sender: AlgoliaSender::new( /* ... */),
}
}
// ...
pub fn place_entity(&mut self, e: &PlacedEntity) {
// ...
self.algolia_sender.add_item(e);
// ...
}
// ...
pub fn placement_done(&mut self) {
// ...
self.algolia_sender.send_items();
// ...
}
}
Marking the data as searchable
To set up our data for the Search UI, we must tell Algolia which attributes to make searchable for better results, as per the documentation:
When you create an index, all attributes from all your records are searchable by default. Having all attributes searchable by default lets you perform searches right from the start without having to configure anything. Yet, if you want to make your search more relevant and remove the noise, you just want to set meaningful attributes as searchable.
For our use case, this “search all” behavior is fine, but if we want a more fine-grained approach we can either use an existing Algolia API Client or the Algolia Dashboard (Note: nested attributes (sub-objects) cannot be added from the Dashboard, only the API).

The search UI
Algolia InstantSearch provides a very easy way to construct custom UIs for browsers that allow us to search our data. We’re simply going to copy the InstantSearch getting started guide and modify it to fit our needs.
We can keep most of the layout and HTML:
<!DOCTYPE html>
<html lang="en">
<!-- exact same <head> as in the demo -->
<body>
<div class="ais-InstantSearch">
<div class="left-panel">
<div id="clear-refinements"></div>
<!-- the only real change is renaming this from "Brands" to "Categories" -->
<h2>Categories</h2>
<div id="category-list"></div>
</div>
<!-- exact same <div class="right-panel"> as the in the demo -->
</div>
<!-- same <script> tags as in the demo -->
</body>
</html>
The Javascript is also almost the same as the demo, except for setting up the Category list instead of the Brands list and changing the displayed hits to contain our attributes.
The only unusual bit here is the customization of the hits to include a custom URL that opens an external editor as a demonstration of Algolia interacting with external applications:
<a href="editor:goto:x:{{root.x}}:y:{{root.y}}:z:{{root.z}}">Open in editor</a>
/* global instantsearch algoliasearch */
const search = // ...same as the demo
search.addWidgets([
instantsearch.widgets.searchBox({
container: '#searchbox',
}),
instantsearch.widgets.clearRefinements({
container: '#clear-refinements',
}),
// categories instead of brands
instantsearch.widgets.refinementList({
container: '#category-list',
attribute: 'category',
}),
// customize the hit display
instantsearch.widgets.hits({
container: '#hits',
templates: {
item: `
<div>
<a href="editor:goto:x:{{root.x}}:y:{{root.y}}:z:{{root.z}}">Open in editor</a>
<dl>
<!-- The attributes we're interested in -->
<dt>Category</dt>
<dd>{{#helpers.highlight}}{ "attribute": "category" }{{/helpers.highlight}}</dd>
<!-- ... other attributes -->
</dl>
</div>
`,
},
}),
instantsearch.widgets.pagination({
container: '#pagination',
}),
]);
search.start();
And with only a few lines of modification, our basic Search UI is ready: we can search for objects, filter them by category, and open the objects in an external editor:
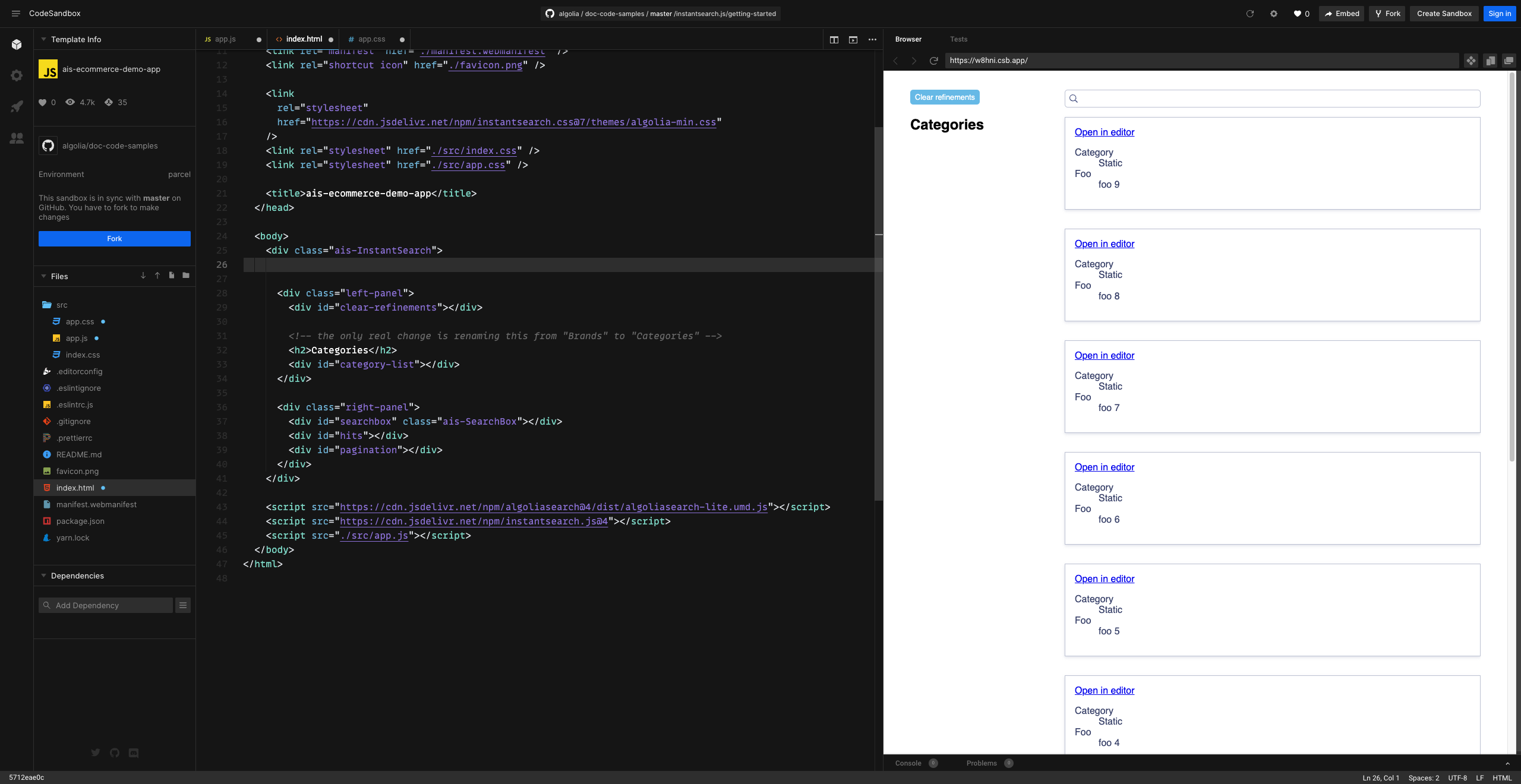
Potential further steps
Async sending of data
The Tokio create provides async support for Reqwest, and can be used to implement async sending of the data. Using an async wrapper complicates calling the exported functions from C / C++ and can mess with CPU core allocation of other running code.
Retry logic
All Algolia clients implement retrying failed requests (and retrying on different target servers). After moving the data transfer to async processing it is relatively easy to add the retry logic as a separate layer.
Less string manipulation
While we had fun format! -ing and concatenating Strings, it would be nicer if at least the objectID generation was more Rust-like: an objectID trait and a nice derive macro would be a better solution for most use-cases, as they allow control and repeatability, but keep the flexibility.
pub trait objectID {
fn object_id(&self) -> String;
}
#[derive(Serialize, objectID)]
#[object_id(prefix="something", field="id")]
struct Something {
id: i32,
}
impl objectID for Other {
// ....
}
We hope that you enjoyed this in-depth article from Gyula, and if you are looking for more content like this, we have many more topics that we’ve covered on the Algolia Blog! If you’re new to Algolia, you can try it out by signing up for a free tier account.
















%20(2).svg)

