This is the result of meticulous research to bring the best of what Algolia has to offer to our documentation users.
Feature highlights
🔍 Spotlight/Alfred-like experience with a result preview panel
🤯 Better relevance with dynamic grouping
⚡️ Smart prefetching for faster access to search results
⌨️ Full keyboard navigation support
🔁 Synchronized search state in the URL (you can now share search results)
☑️ Explicit filtering right from the query with Quick Filters
❓ Insightful no results state with Query Suggestions and results without filters
📱 Refined mobile and tablet experience
✨ Focus on UX with a clearer interface, micro-interactions, and many patterns inspired by native experiences
If you’ve never used the Algolia documentation search before today, we used to provide search results in a sliding panel (see image below). The experience was alright, but conventional; a tabbed experience with two sets of paginated results.
On the relevance side, we had received several complaints. The existing code had become too complex to fix. It had evolved a lot through the years, and it was no longer suited to the current state of the docs.
The previous documentation search experience.
We went back to the drawing board and redesigned everything from the ground up.
Overhauling the interface and user experience
Searching through content is different from searching for items to buy. People formulate things differently from how it’s written in source content. As a result, the search process can take more back and forth. We wanted to acknowledge this behavior by making it painless for users to refine their queries while offering cues to discover results and confidently pick the right one.
At Algolia, the Documentation team works closely with the InstantSearch and DocSearch squads. We were able to take many shortcuts by working together and reusing research from building Autocomplete v1 and DocSearch v3.
Search and discovery
The new search offers a Spotlight/Alfred-like experience. Whatever you do, you always remain focused in the search box. This lets you refine the query as you need.
We display a list of results on the left and a preview panel on the right. This lets you discover more about your search results before deciding whether you want to navigate to the associated resource or not.
A rich preview panel lets you explore search results before navigating.
Everything at your fingertips
Thanks to Autocomplete v1, we now offer a state of the art autocomplete experience with enhanced accessibility and full keyboard navigation support.
You virtually don’t ever need to use your mouse. It makes the process of refining your query even more seamless.
You can virtually interact with every part of the search with your keyboard.
Only the best results
You might notice that the search isn’t paginated. This is by design. We believe that the best results should always be on the first page. Making users go through pagination is taking them on an unsatisfying path of less relevant results.
Instead, we provide a set of Query Suggestions at the end of the results list to let you refine your query and yield better results.
Instead of endlessly scrolling through pages, you get to adjust your query to trigger better results.
Agile filtering with Quick Filters
In the previous experience, we applied filters automatically, but in an opaque way. You didn’t know what filters were being applied, and some of them would depend on your local preferences. This made the feature unpredictable and hard to debug.
We wanted users to be able to explicitly pick filters, with no surprises. We went through two iterations, and after gathering feedback and watching people use them, we landed on Quick Filters. We suggest filters directly from the search box, as you type, and let you apply them or not. You can keep typing your query and replace or delete filters without ever leaving the search box.
Quick Filters trigger as you type to offer filters suggestions.
This is an experimental feature, and we’re eager to see how people use it. We’re planning on leveraging Algolia’s search for facet values feature to enhance the experience even further, by offering more, typo-tolerant suggestions.
Never let you down
Isn’t it frustrating when you land on a 404 page and it doesn’t guide you anywhere? We feel the same way about unhelpful no results pages.
Instead of punishing you for typing the “wrong” query, we provide a more welcoming and forgiving experience by letting you know what’s wrong and what steps to take next. Whenever you have filters that return no results for a given query, we immediately perform another search without filters. This way, we can show you that there are matches without the filters you have on.
The experience remains the same, all we do is letting you know.
We display results even when filters get in the way.
If the search still yields no results even without filters, we offer Query Suggestions so that you’re always able to move forward.
We’ve redesigned and optimized the tablet and mobile experience so that you can comfortably search even from your phone. All features work on mobile, including Quick Filters.
The preview panel makes no sense on mobile devices, because you can’t hover or navigate with a keyboard. Therefore, we replaced it with a short description in the search results.
Rethinking documentation relevance
When you’re working with documentation, you’re handling interconnected pieces of information. It is fundamentally different from an eCommerce experience, where items are mostly independent.
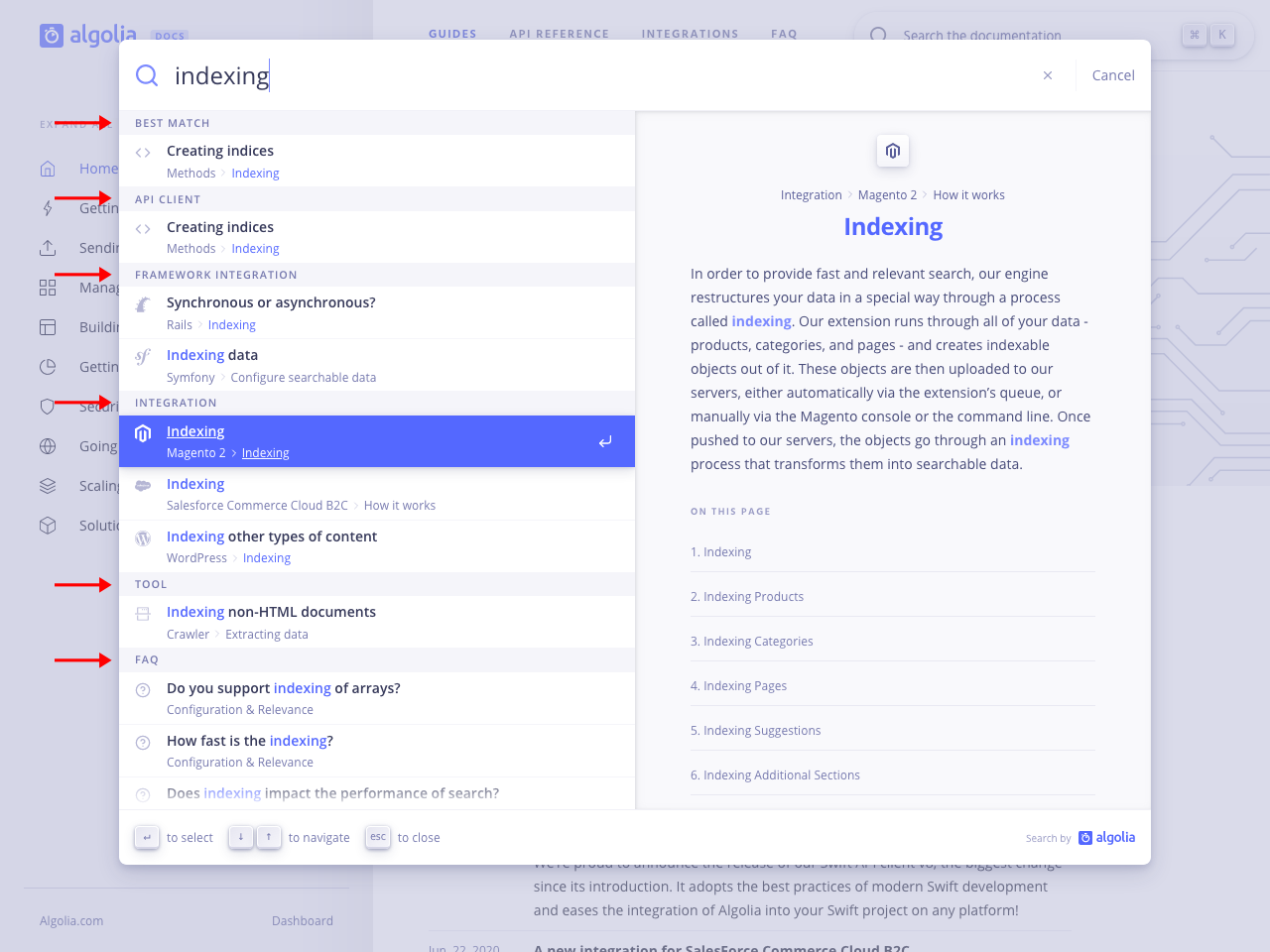
A documentation resource can be part of a series or an appendix to a canonical guide. A page is broken down into single paragraphs to fit into Algolia records. When you’re searching for something in a documentation website, it maps to a single search result. Yet, for you to understand it and decide which hit makes the most sense among many, you need context. For example, when searching for “indexing”, you’re likely interested in indexing your data. However, there’s no way for Algolia to know what you’re precisely looking for at this point: guides on how to index data, API reference for a given language, pricing concerns, etc. If we solely rely on Algolia’s ranking strategy, we’ll get the most textually relevant results first. It’s a good start, but it isn’t enough.
Dynamic federated search
We created a dynamic federated search experience. We rely on a single index and handle the category grouping on the front end. No empty or statically positioned category, no lack of balance between categories. We rely on Algolia’s powerful API to return the best matching results in record time, and we give them more meaning with business code.
Results are categorized dynamically, to create context and help users scan them.
How it works
When we receive hits from Algolia, we assume that they’re all relevant. The first thing we do is group them by type (integrations, InstantSearch widgets, FAQs, and so on). We then assign each category a score to sort it in the UI. This helps us control the order, so that users can expect certain types of results to always be at the same place. Guides are usually at the top, and REST API pages at the bottom.
We rely on Algolia’s first match to display the best matching at the top, but only if the first result of the grouped hits is different.
Since we don’t rely on multi-index search, we can’t control how many hits we get for each group. This could lead to unbalanced results, where you’d get ten guides and two API reference pages. This would fail at surfacing a variety of content. Therefore, we adjust the number of hits to display in each group. If there are ten matches in both integrations and widgets, we don’t show twenty matches, because it would bury the second group and force users to scroll. Instead, we cap the number of hits by the total amount divided by the number of groups.
When Algolia returns hits from a single category, the algorithm displays them all, as it’s likely the type of content you’re looking for. If it returns hits from a second category, we cap it to half for each group.
So far, this grouping and capping logic has created a pleasant experience which feels natural and transparent.
All this front-end logic doesn’t mean we’re disregarding Algolia’s ranking strategy. We rely a great deal on Algolia, and we improve its ranking for the use case of documentation. Algolia returns results that we know are relevant, so we have a good base to start from. It also provides a “pre-ranking” that we rely on for most content types. Many of the scores we assign are equal, which means we default to Algolia’s ranking to break the ties on these.
Supercharging the indexing pipeline
We couldn’t talk about the new search without mentioning indexing. It’s the first thing we redesigned, and we managed to make it faster than ever.
To each their own
One of our pain points was to add new kinds of content. The way we index data is different depending on the type of page. You don’t pick up the same information when you index an FAQ and a Crawler parameter.
Our legacy indexing pipeline was designed before we had such diverse products in the documentation, so it wasn’t optimized for this use case.
The new indexing pipeline makes it a breeze to add new content types: every type of content gets its own record builder. If we need to document a new product, library, or integration, all we need to do is write a builder for it.
Each content type has its own record builder.
Could this BE any faster?
We’ve also improved our indexing pipeline’s performance by generating multiple records simultaneously. We leverage a technique to ensure that all tasks are finished without waiting for all of them. This reduces stress on the engine, and shaves off some extra time on our end.
Generating a full index for the documentation used to take over 13 minutes. With the new pipeline, it goes down to around 4 minutes to extract data from over 1,300 pages, run sanity checks to ensure data integrity, and index over 50,000 records. This is almost4 times as fast. When we only update the records that need changing, the indexing is even faster. During a typical deployment, an incremental reindexing now takes less than 3 minutes. This lets us iterate faster and publish new content quicker than ever before.
A full reindex with the new pipeline.
What’s next?
We’re thrilled to be releasing this experience, and we see it as the first step of building best in class search experience that helps and inspires our users. Here are ideas we already have in the pipe:
🎙 Algolia Answers & Voice Search support with the Web Speech API
💻 OpenSearch support to search in the Algolia docs from your browser’s URL bar
This makes us confident about releasing the v1 of Autocomplete, as we’ve now used it in several projects with high visibility.
We’re also working on bringing all the features of the new Algolia documentation search into Autocomplete in the form of plugins. This way, you’ll be able to create a similar experience with your DocSearch-powered documentation site, or using the library directly. Stay tuned on our Discourse forum!
Gartner 2026 Magic Quadrant for Search and Product Discovery
A leader for the third consecutive year
Algolia is recognized as a Leader in the 2026 Gartner® Magic Quadrant™ for Search and Product Discovery as the market shifts toward AI-powered, agentic discovery.
Increased Operating Profit and Improved Efficiency
A Forrester Consulting study found Algolia delivered $3.1M NPV over three years, helping commerce teams improve relevance, automate merchandising, and grow revenue
IDC recognized Algolia as a leader in general-purpose knowledge discovery software, citing the growing role of search in AI-powered workflows and enterprise knowledge experiences
Algolia earned 12 medals across 12 categories in Paradigm B2B’s 2025 Enterprise Combine for Search and Discovery, with customers praising speed, transparency, analytics, and ease of use





















%20(2).svg)











