For many years search engines have predominantly relied on keywords, much like the indexes you find in the back of books. Unless a query matches a keyword in your index, the search engine can come up empty-handed. While the concept of “matching” has traditionally powered search engines, a major shift from “matching” to “understanding” is currently underway. This is being driven by AI, which is used to represent text mathematically such that it can be conceptually understood by machines. Concepts are taking over from keywords and it’s great news for everyone.
In this article, I’ll explain a bit about what concept search is and how the semantic machine learning technology around it is changing. It’s helpful to first understand the limitations of traditional keyword-based models.
Background on search
Around 80% of all data applicable to business is unstructured (as opposed to structured data like age, weight, price, addresses, etc.). In order to find things in unstructured information, search engines have been the tool of choice. The main methodology behind this has been the tokenization of keywords, which splits text into common pieces (essentially lookup keys) which are then used to build indexes.
Each token (word, phrase, ngram, stem, lemma, etc) is linked to the records where it occurs. The same tokenization process is then applied to queries, the resulting tokens can then be used to find matching items and this “matching” process forms the basis of keyword search retrieval. In this context retrieval means to retrieve relevant matches for a query. Ranking is then typically used to order the results in the most useful order.
Term frequency – inverse document frequency (TF-IDF)
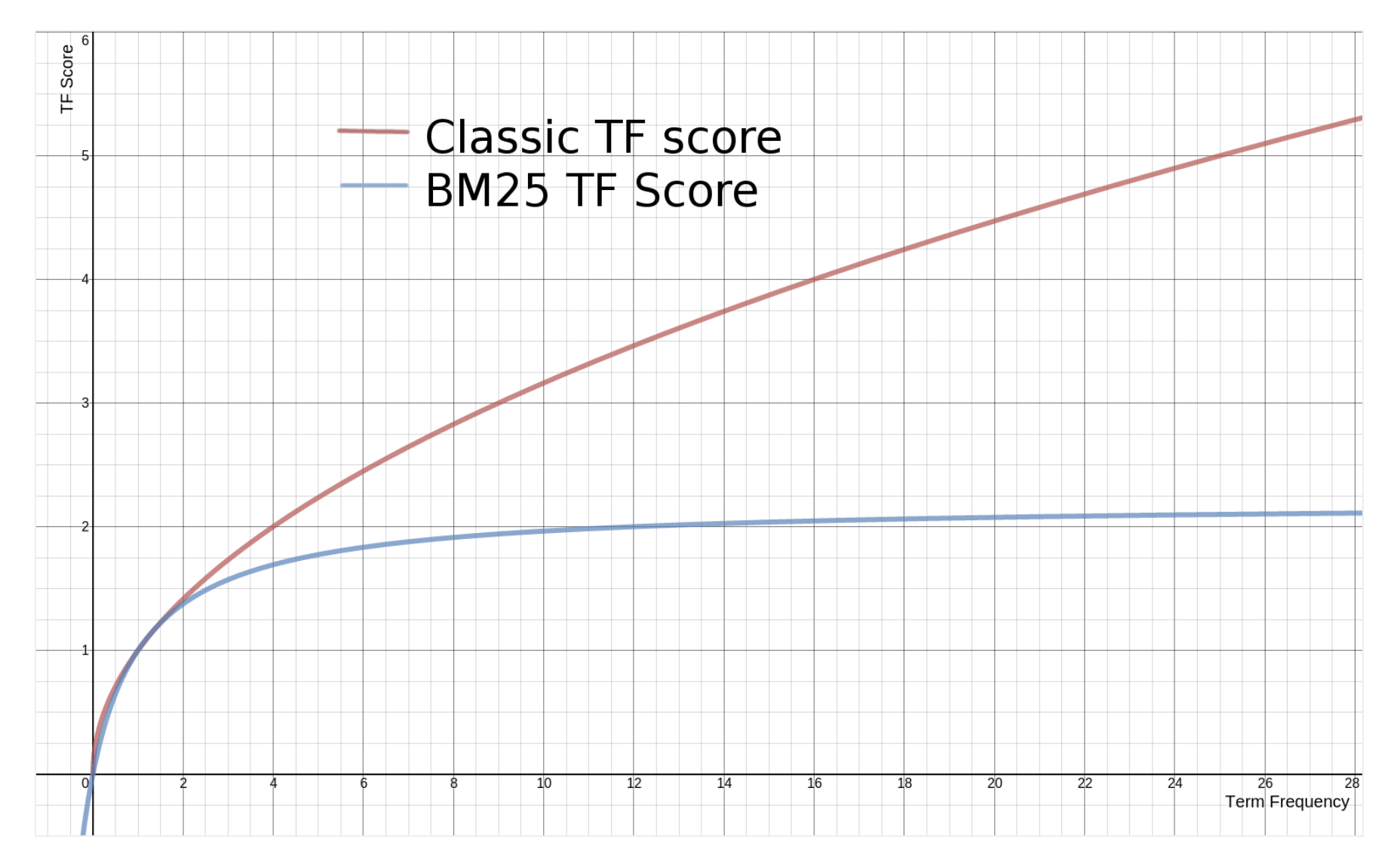
For some time TF-IDF was the standard for keyword search. This formula looks at the Term Frequency (TF), which is the number of occurrences of a keyword in a matching document (more is better) and Inverse Document Frequency (IDF), which looks at how popular the keyword is in the document corpus (less popular is better, hence the “inverse”).
BM25
TF-IDF worked ok, but the gold standard today are variants of BM25. BM25 looked to solve some of the deficiencies of TF-IDF, mostly that TF is very susceptible to spamming. It introduces a dampening to the TF formula so more matches are increasingly less important as per below. It also uses a document length to correct for longer documents containing more keywords.
Today the most important variant is BM25F, which includes relative field importance in the calculation. This allows a title match to be more than a match in the middle of the document text etc.
Before pointing out the issues with BM25F, keep in mind this is still the gold standard in 2023 for keyword search. This is the benchmark technique to beat in academia.
Everything mentioned above works on a “bag of words” approach. The sequence of words is ignored and only their individual intersection with the target document is important. This has many problems in real world search scenarios, particularly shorter form structured data.
As organizations moved online, enterprise search became a key requirement for knowledge management. As data and information assets in general further exploded in volume, the importance of enterprise search has only increased exponentially. Yet without document enrichment with intelligent metadata, auto-classification, taxonomy management, and other methods of adding structure, relevance has typically been poor. The result is that people at work cannot find relevant documents — and this is a big problem.
Why are keywords problematic for search?
Keywords are hard for search engines. You have synonymy (multiple words with shared meaning), polysemy (words with multiple meanings), sequence (order is sometimes important but not always), abbreviations, asymmetry (query words not expected to appear in target results), and more.
In general, keyword search implies you already know the answer to what you’re looking for and how it will be explicitly described. For example:
You search for “crewneck” and you don’t find “tshirts”.
“usbc” vs “usb-c” or “usb c”. Some variations have many results and some show no results.
“dress shirt” and “shirt dress” return the same results even though the meaning is very different
“room safe” and “safe room” use the same terms but mean very different things!
There are workarounds to these problems, but they can be time-consuming and never-ending.
In a traditional sense the goal of search is to take a query and try to find occurrences of it in a set of items, much like the index in the back of a book. This assumes a symmetrical relationship between the query and result text, i.e., you search with the answer, not with the question. Symmetry assumes you already know the answer.
The context of keywords is typically not useful enough to determine the searcher’s intent. Take the simple example of “bank”. When someone types this, they could mean:
Financial institution
Side of a river
Basketball shot
An aeroplane turning
Above is a good example of polysemy. This can also be extended to asymmetry. For example, if someone searches for “plane turning” this may not return a result that says “plane banked”, yet the meaning is similar. “Plane” itself is also an example of polysemy and an abbreviation of “aeroplane”!
Compound term processing works to combine terms into groups that have their own meaning that is different from the individual terms. One example is “new jersey”, which has totally different meaning to “new” AND “jersey” as individual terms. In practice, keyword search usually handles the compounded queries well; it typically requires all terms to match, scoring sequences higher than containing all individual terms. However it struggles with partially compounded terms, “bank” being a great example. It will match all contextual occurrences of “bank” as there is no way to determine which context is correct.
Note: the above is also assuming queries are treated as AND (require all terms to match). In practice, some keyword search uses OR, which can match any of the query terms and is thus far more likely to return contextually irrelevant results. Some search technologies also use a hybrid approach which treats some text as AND and others as OR, which can be smart or naive in nature. Boolean search is a way to give the searcher access to control how things are matched by allowing the use of syntax in the query such as quotes, “AND”, “OR”, and “NOT” operators. This can be useful but is generally beyond comprehension for the average person searching.
Keyword search works well for the “fat head” queries that represent the most popular searches. However, “long tail” searches frequently fail, and they can be 50% or more of the queries in your catalog. The ways that keywords fail when searching are endless. People have spent massive amounts of time writing rules, dictionaries, synonym libraries, and more. As I’ll show, keywords are still quite useful, but they’re even better when paired with AI.
How concept search works
Keywords (and their associated tokens) are relatively binary in respect to search, particular words either exist or they do not. Concept searching is based on vectors. The mathematics of vectors allow for the measurement of closeness, thus the relationship of text is no longer binary but rather a distribution.
How vector search algorithms measure closeness.
Text is represented as vectors, and text with close conceptual meanings share very similar vectors. Typically the vector orientation is used rather than the magnitude, so the angle between the vectors becomes a measure of similarity. This is called cosine similarity and would be very familiar to anyone who has done high school math! The only difference is that vectors representing text use hundreds of dimensions, so it’s harder to visually represent as per above (2 dimensions).
Text to math
How is text turned into vectors? Neural networks are used to look at word sequences and build vector-based models that can convert text to vectors, called embeddings. There are many examples of these and more appearing all the time. For example, AirBnB uses embeddings to help power their similar listings feature.
Using concepts in search
Concepts are great, but they also blur out the query meaning, so keywords are actually still useful. Thus, state of the art search is actually built on what is called “hybrid retrieval”, which is a combination of keyword and concept-based search.
Here are some of the ways we designed hybrid retrieval in our new AI engine.
Sparse retrieval is based on keywords. This is analogous to the back of a book when you look up a word and which pages it appears on. There are some language tweaks like lemmatisation, stop words, synonyms, and such, but for the most part the query either is or isn’t in the target results.
Dense retrieval is based on matrices. Text is converted into math (vectors or hashes) and proximity is used to infer relatedness. This solves many issues with the exactness of keyword search, but can be very expensive to do. That is, if not combined with another technology called neural hashing. For sparse retrieval you look at the list of matching items to each keyword (typically this is a small number of items). For dense retrieval you don’t know from any one number in the vector/hash, so you need to scan lots of information. While this has made it to date relatively cost prohibitive and slow, hashes have changed this.
Hybrid retrieval combines dense and sparse retrieval. Keyword matches find the exact hits where symmetry is suitable (typically head query terms), dense retrieval fills in the long tail gaps and handles all the problems with keyword search described above. Dense retrieval removes the need for synonyms & most rules, understands questions (asymmetry), and much more.
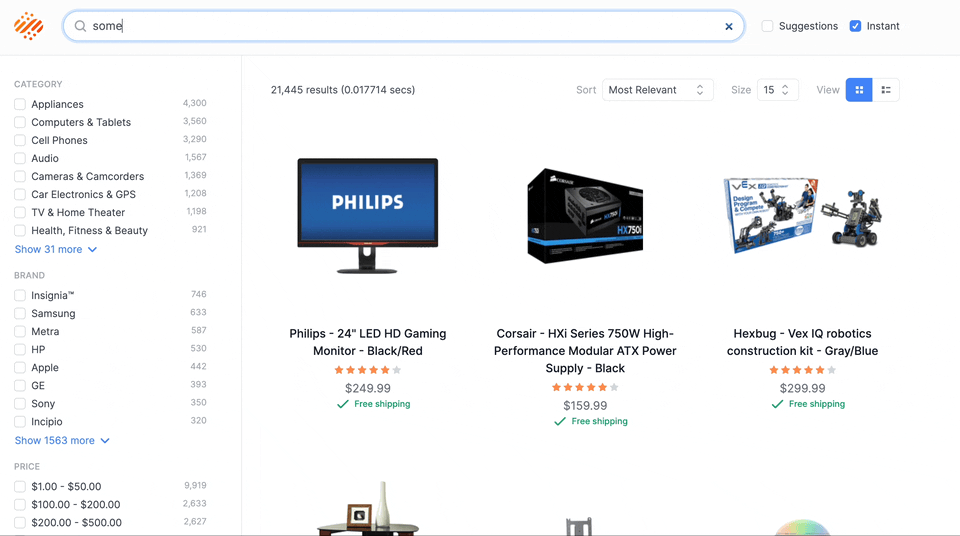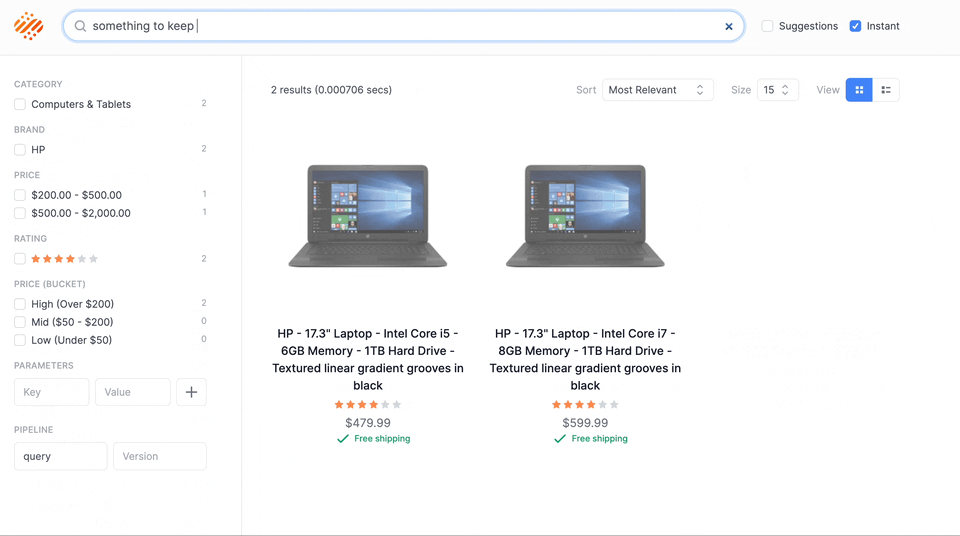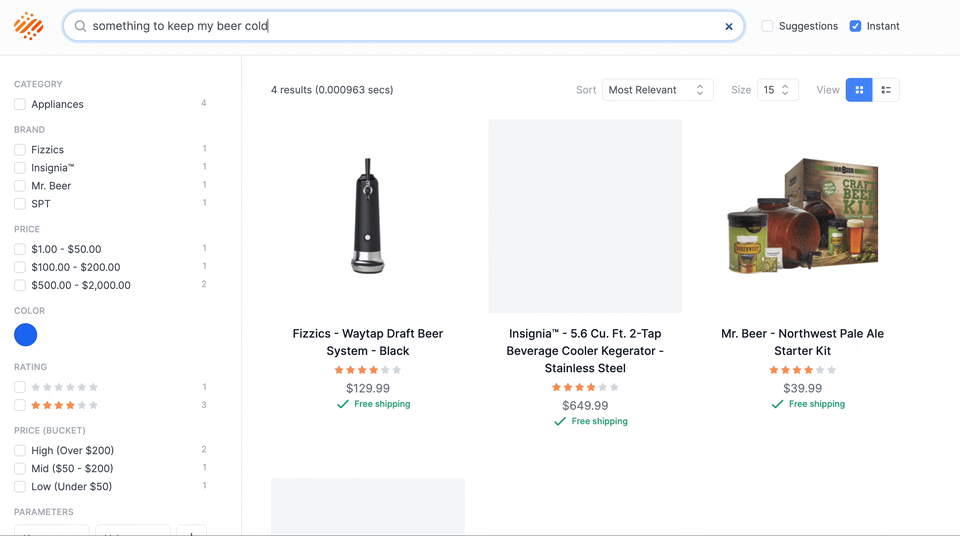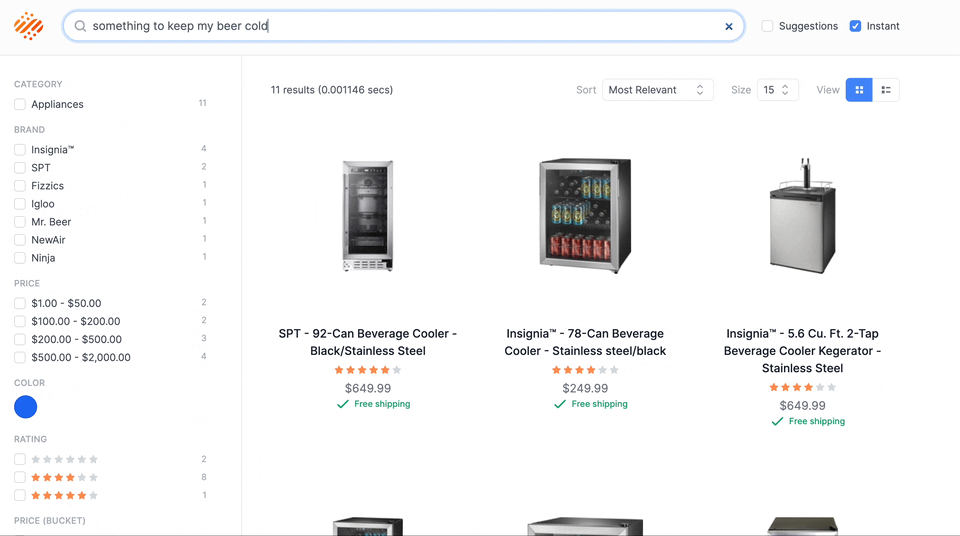
With the addition of neural hashing, Algolia is the only company with a scalable hybrid offering capable of working for many different use cases right out of the box. We can now offer search that is just as fast (and often faster) and more accurate than keywords-only. One of my favorite examples is running a query on a Best Buy dataset for the phrase “something to keep my beer cold.” If someone walked into your store and asked for “something to keep my beer cold,” you would know exactly what they mean. A keyword-only search engine would have a rough time. However, a hybrid retrieval engine is able to understand the concepts to deliver incredible results in 0.001043 seconds!
An example of concept search.
Our demo site doesn’t contain any additional metadata. The terms “cold” and “beer” don’t appear on any of the records on the site, but the site understands the concepts!
Stay tuned. The new Algolia search experience is coming soon! Or, sign up to be notified when it’s available.
Gartner 2026 Magic Quadrant for Search and Product Discovery
A leader for the third consecutive year
Algolia is recognized as a Leader in the 2026 Gartner® Magic Quadrant™ for Search and Product Discovery as the market shifts toward AI-powered, agentic discovery.
Increased Operating Profit and Improved Efficiency
A Forrester Consulting study found Algolia delivered $3.1M NPV over three years, helping commerce teams improve relevance, automate merchandising, and grow revenue
IDC recognized Algolia as a leader in general-purpose knowledge discovery software, citing the growing role of search in AI-powered workflows and enterprise knowledge experiences
Algolia earned 12 medals across 12 categories in Paradigm B2B’s 2025 Enterprise Combine for Search and Discovery, with customers praising speed, transparency, analytics, and ease of use

















%20(2).svg)










