If you’re building a documentation site, your content needs to be easy to write and easy to search. Combining Astro’s Starlight framework with Algolia gives you the best of both! Let’s look at each of these tools, see when Algolia is the right fit, and learn how Starlight’s plugin system lets you add Algolia DocSearch.
Astro is a full-stack JS framework for building content-focused websites. Its claim to fame has been its support for any UI component framework (React, Vue, Svelte, etc), letting you bring the tools you know to build marketing sites, blogs, and yes, docs.
Starlight is an Astro theme specifically focused on documentation. This meta-framework offers first-class styling, internationalization, and support for popular content authoring formats like Markdown and MDX. The framework is also extensible, with options to override built-in components and introduce “plugins” that configure deeper internals.
What is Algolia DocSearch?
Algolia DocSearch is a search service focused on dev tool documentation, trusted by popular web development tools like Vue.js and Laravel. Algolia crawls your site as a regular cron job. For search, you can embed Algolia’s ReactJS widget on your documentation site, and let Algolia manage search results for you.
Algolia vs. Starlight’s built-in search
Starlight uses a built-in, open-source search client by default, which works for anyone trying it for the first time or working on very small projects. However, Algolia DocSearch is worth the upgrade if:
You want access to search analytics. Starlight runs searches against a prebuilt index map without any analytics service attached. Since Algolia DocSearch is hosted, you can see insights for popular queries to ensure the right pages are surfaced.
You want deeper customization of your search results. DocSearch gives you access to Algolia’s entire dashboard to adjust search indexes, set synonyms for key phrases, and make other tweaks to improve output. Starlight’s built-in search is far more spartan.
You plan to index server-rendered content. All Starlight projects are statically generated, meaning pages are compiled to HTML assets (and therefore compiled into your search index) before you deploy to production. Meanwhile, Algolia crawls all possible routes on your site and indexes on their backend servers. This means dynamically rendered content can be crawled without the need for static builds. This is helpful if you ever migrate your Starlight site to a server-rendered Astro site, say for authentication gateways or A/B testing.
You will need a Starlight project deployed to production to try DocSearch. This should be the production URL you used when applying to DocSearch.
If you need a Starlight project, you can visit the quick start guide or clone our own Starwoof example. This is home to the Astro team’s diverse family of pets, meows and oinks included 🐷
If Pan doesn’t sell you on Starlight, I don’t know what will
Set up the DocSearch plugin
The DocSearch Starlight plugin is available on npm:
Apply this plugin to the Starlight plugins array in your astro.config.mjs file:
import { defineConfig } from 'astro/config';
import starlight from '@astrojs/starlight';
import starlightDocSearch from '@astrojs/starlight-docsearch';
export default defineConfig({
integrations: [
starlight({
title: 'Site with DocSearch',
plugins: [
starlightDocSearch({
appId: 'YOUR_APP_ID',
apiKey: 'YOUR_SEARCH_API_KEY',
indexName: 'YOUR_INDEX_NAME',
}),
],
}),
],
});
You may prefer to load these variables from a .env file. Astro recommends using the loadEnv utility for this (see documentation).
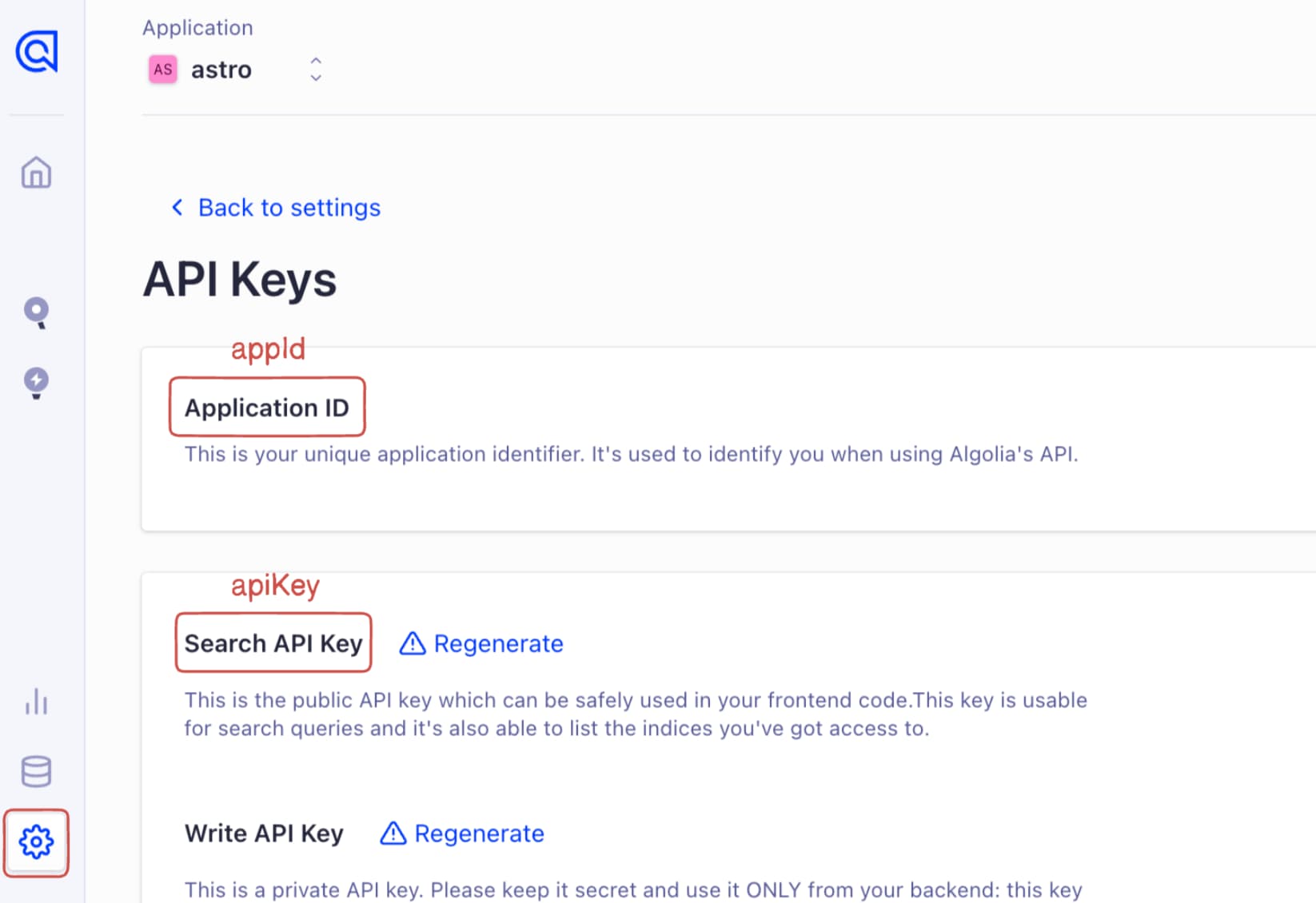
Note you will need three variables: an App ID, a Search API Key, and an index name.
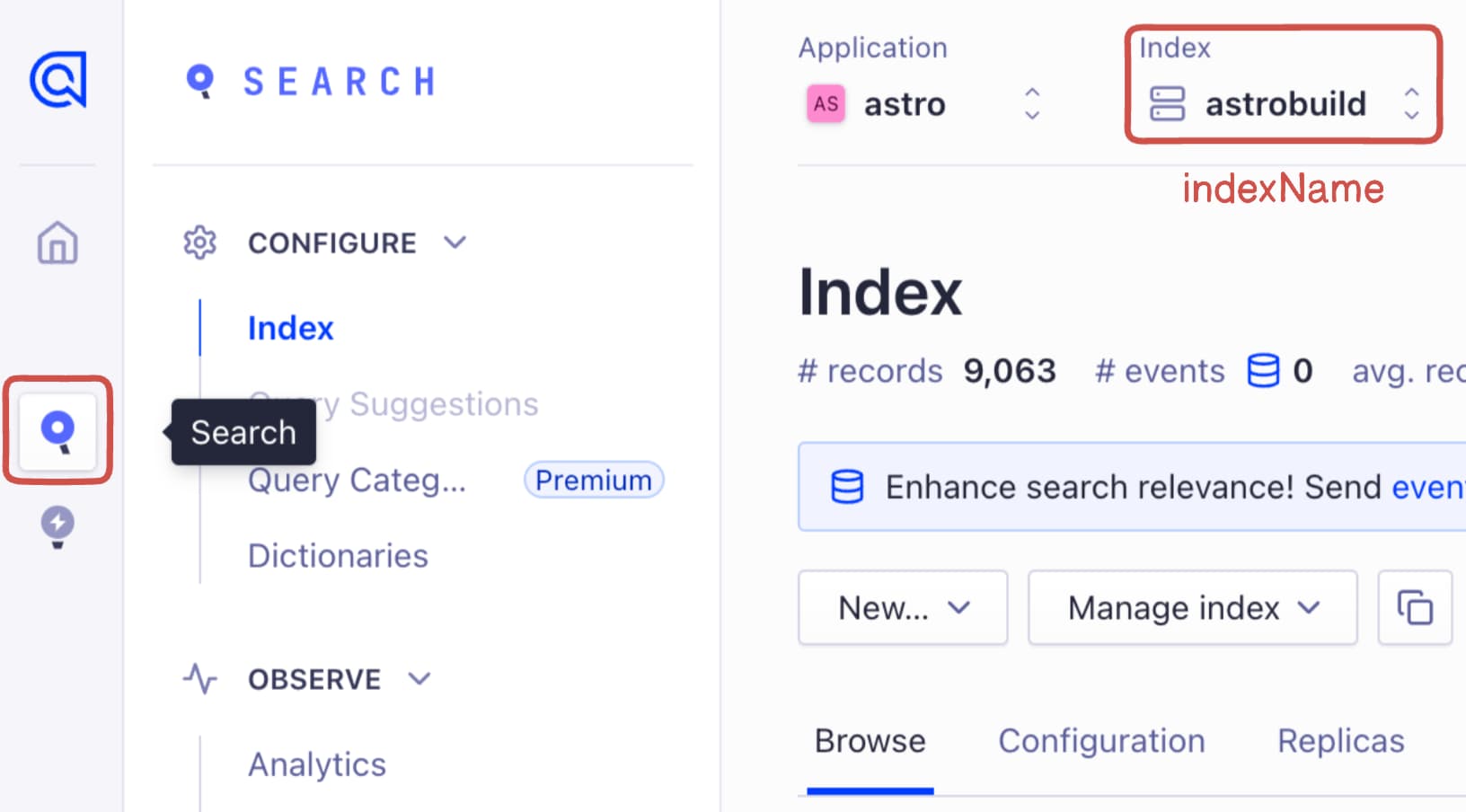
The index name is attached to your crawler. This is created while registering your DocSearch account to scrape your website content and generate a search index. You’ll find your index name on your Algolia dashboard under the “Search” tab:
For your Application ID and API Key, visit the “Settings” tab:
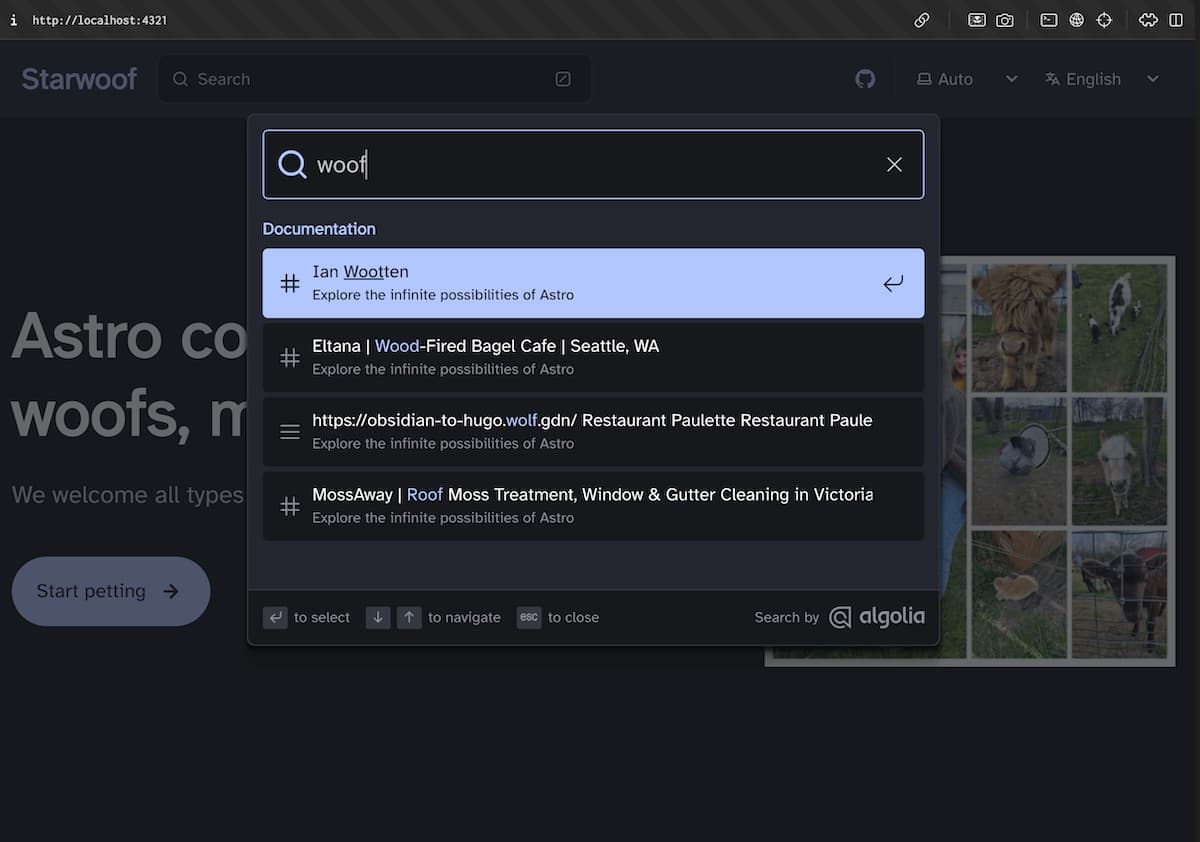
Once these variables are defined, start the development server. You should see the Algolia search dialog appear when you hit / on your keyboard:
Conclusion
Algolia DocSearch is an upgrade to Starlight’s built-in search for growing docs sites. If you need the analytics and SSR flexibility, apply to the DocSearch program. Happy doc-ing! 👋

















%20(2).svg)

