In any search engine, adding synonyms is one of the most important customization to introduce domain-specific knowledge. Synonyms make it possible to tune search results without having to make major changes to records.
Supporting synonyms is no easy task especially for multi-word expressions, which introduce complexity in the handling of the proximity measure between matched words. We will describe in this post how we handle this complexity via a rewriting of word positions at query time.
Different types of synonyms
The most common way to define synonyms is to use a set of expressions that are all identical. We call such a set an N-way Synonym because any expression of the synonym set is a synonym of another expression.
For example, if New York is unambiguously a City in your use case, you probably want to have a synonym set containing “NY” = “NYC” = “New York” = “New York City”. This synonym set is configured as N-way, which means that:
- “NY” in the query also matches “NYC” or “New York” or “New York City”
- “NYC” in the query also matches “NY” or “New York” or “New York City”
- “New York” in the query also matches “NY” or “NYC” or “New York” or “New York City”
- “New York City” in the query also matches “NY” or “NYC” or “New York”
Less common but still used are asymmetrical synonyms, in which you want to apply an equivalency only in one direction – we call this a 1-way Synonym. For example, “smartphone” = [“iphone”, “android”] means that you want the “smartphone” query to be expended in “iphone” and “android” because you can have a record containing iphone without having the word smartphone. That said, you do not want the query “iphone” to returns all records containing the word “smartphone” – that wouldn’t be relevant for the user.
The Algolia engine supports both 1-way and N-way synonyms, and both types can contain any type of expression (one word or multiple words like “New York City”).
The dangers of generic synonym sets
We are often asked by users when we will include a standard synonym dictionary in the engine. The question is understandable – after all, we are taught in school that most words have synonyms, so it seems easy to package all this knowledge into one generic resource (per language). Unfortunately, it’s not that simple.
There are varying degrees to which two words or phrases are synonymous. For example, “substitute” is a stronger synonym to “alternative” than “choice” even if you can find both in a standard English synonym dictionary. Adding “substitute” as a synonym of “alternative” can be a very good idea for a website that compares technologies or offers; that being said, it can easily add noise on other use cases, especially if the name of a technology contains “substitute” in the name like the Substitute or jquery-substitute open source projects.
Polysemy is present in all Natural languages, which means that a word can have different meanings depending on the context. For example, the word “crane” can be a bird or a construction equipment and the context is required to select the correct meaning. Our customers are all in a specific semantic context and the dictionary need to be specific to give the best results. If you are on a tech website you don’t want to have a generic synonym of the word “push” because there is a strong meaning in tech and using synonyms for the verb or the noun “push” would lead to weird results.
The most useful synonyms are always very specific to your domain. This is the case of the synonym set [“NY” = “NYC” = “New York” = “New York City”] we mentioned before. This synonym set is valid if you only have cities in your use data set, it could introduce a bad relevance if you also have States!
Even specific synonyms can have a different meaning in another use case. For example, I saw the synonym T-shirt = Tee on several ecommerce websites. This synonym makes sense as a lot of users are typing “tee” to search for a t-shirt. That said, this synonym is dangerous if you have a sports website as you can have a query for “tee ball” or “golf tee” and won’t like to return t-shirt!
With all those constraints in mind, it is close to impossible to package a set of synonyms that would make sense for all use cases as it is too much use case dependent. In practice it would lead to a bad relevance and results would be hard to understand for your users.
This is why we do not plan to package a generic synonym dictionary in the engine. That said, there are other resources that we already package in a generic way like the singular/plural forms of a language that we expose in the ignorePlurals feature. We plan to continue introducing such resource in the future that provides a lot of value without having the drawback described before.
Computing synonym at indexing or query
One of the main question with synonyms is to make the choice between pre-computation at indexing time or expansion at search time. Both approaches have advantage and drawbacks:
With pre-computation at Indexing time, if you have a synonym “NY” = “NYC”, you will index the document with both words when one of the two words is found in a record. This method is the best for performance as there is no OR between the two synonym words at search time. The biggest issue with this approach is to introduce the support of multi-words synonyms, which require introducing a new knowledge in the inverted list.
For example, if you have the text “New York Subway”, the word “New” will be indexed as position 0, the word “York” will be indexed at position 1 and the word “Subway” will be indexed at position 2. If you have a synonym “New York” = “NY”, you will have to introduce in your index the token “NY” at position 0 with a padding of 2 positions so that the query “NY subway” will have correct positions. This additional information has a big impact on the index size and performance that usually nullify a lot the gain of indexing in most use cases.
Conversely, with computation at search time, you will search for all synonyms at query time with an OR operand between them. The big advantage of this approach is that you can compute the exact position of each matching synonym with a post-processing task (see next section for details). The disadvantage is that it requires more CPU as we have to compute the OR between several inverted lists.
Lastly, A hybrid approach is a mix of both approaches where all synonyms are searched at query time but some expensive computations are precomputed in one inverted list. Most of the time the expensive computation that is indexed is the search of consecutive words (phrase query). For example, the “New York” synonym would be indexed as one inverted list. The complexity of this implementation is to make it work with prefix search as we will describe below.
The implementation of synonyms in the Algolia engine is fully done at search time as we want to have an exact computation of the proximity (see next chapter for more details). We plan to implement a hybrid approach in the future where phrase queries will be pre-indexed in order to improve performance and have the best of both worlds.
Handling multi-words synonyms is hard
Even if our implementation is currently fully done at search time, we are still forced to rewrite the matched word position in order to have an exact computation of the relevance. We have explained in details this process in part 4 of this series in section 2.3.2.
Without this processing, having a synonym “NY” = “New York” would lead to different proximity for the query “New York Subway” on those two records:
{"Title":“Why New York Subway Lines Are Missing Countdown Clocks”}
{"Title":“NYC subway math”}
The complexity is that “New York” is identified as position 1 and 2 in the first record, followed by “Subway” at position 3, whereas the second record contains “NY” at position 0, followed by “subway” at position 1. Rewriting this will ensure the proximity measure between the matched word will be identical for both records. This process essentially considers that “NYC” was composed of the two original words “new” and “york” and will increase all following positions.
The following diagram shows the transformation done on the position of words to have an exactly identical proximity computation for records with a different number of words in the synonym (Note: words are indexed starting at position 0. For example, the first record is indexed with “why” at position 0, “new” at position 1, etc.)
.png)
Reducing noise in results
Synonyms are just one of the various alternative expressions that are added on the queries. We also add typo tolerance, concatenation & split of query terms, transliteration and lemmatization. All those alternative expressions are described in the part 3 of this series.
In order to avoid adding noise, we do not apply the other alternative expressions on synonyms. This is the big reason why a search for “New York” won’t give the same number of hits than “NY” when you have a synonym “NY” = “New York”, records containing “NY” and “New York” will be retrieved in both cases but the record containing “NewYork” for example will be only returned for the “New York” query via the concatenation expression.
The following diagram explains the way we add alternative expressions, all steps are computed at the same time and are not re-entrant. In other words, we do not use the output of one alternative expression to feed the input of another step.
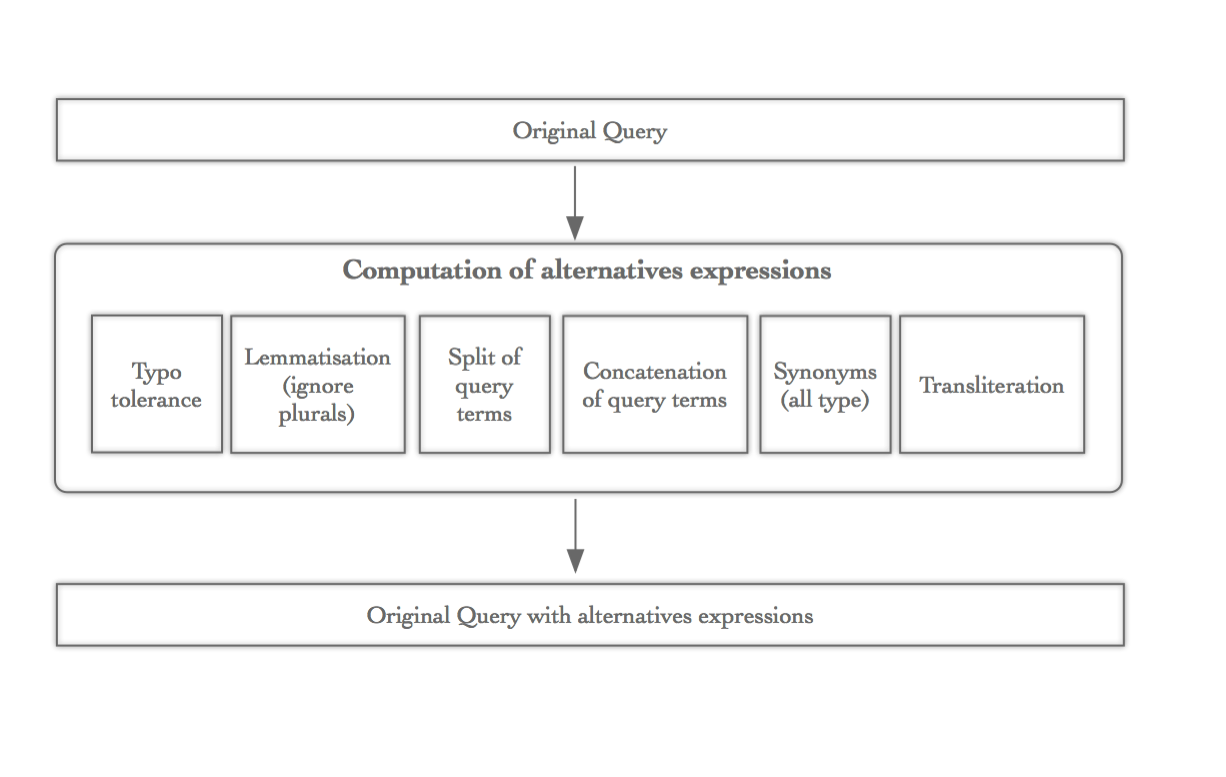
Prefix match on synonyms
Handling synonyms correctly in an instant search use case is pretty complex. Most engines fall short in this respect and have a bad user experience because of this processing. For example, let’s say you have 5 records containing “NY” and 5 records containing “New York” and have defined the synonym “NY” = “New York”:
- the query “n” will match all words starting with “n”, so records containing “NY” and “New York” will be matched: the 10 records are found
- the query “ne”, “new”, “new y”, “new yo”, “new yor” will only match the 5 records containing “New York” as the synonym is not triggered
- The synonym will only be triggered when the query contains “New York”, returning the 10 records
In order to avoid this flickering of search results, we consider that the last word of an expression is allowed to match as a prefix. So the synonym will be triggered as soon as the query contains “new y” (of course the synonym will also be triggered for the query “new yo”, “new yor” and “new york”). This approach reduces a lot the problem of flickering as the synonym is added as soon as the last word is started and deliver an intuitive behavior:
- It would be very complex to understand that the query “ne” match “NY” because we match a prefix of the expression “New York” (would be the case if we allow to match the complete synonym as a prefix)
- It is pretty easy to understand that the query “new y” is matching as a prefix of “New York”
This is why, in the Algolia engine, the final word of a synonym expression can be matched as a prefix. Of course, we continue to add the synonym when the expression is only a part of the query, so the query “New York subway” will still match the synonym “New York” = “NY” and records containing “NY” and “subway” will match. This recognition of expressions at any position of the search query is not performed by most engines.
Difference between original terms and synonyms
Most users want to consider synonyms exactly identical to the search terms but this is not always the case, as we described before there is several degrees of synonyms and some synonyms are closer than others.
We have several tunings available in the engine to let you configure the way to define the expressions that should be considered as identical or not:
alternativesAsExact is an index setting that specifies the type of alternatives that should be counted in the “exact” criterion of the ranking formula. As we explained in detail in part 4 of this series, it counts the number of terms that exactly match the query. By default, this settings is set to [“ignorePlurals”, “monoWordSynonym”], which means that the singular/plural alternative and the synonyms containing one word are considered as exact but a synonym containing several words won’t be considered as exact as they are often semantically farther. You can consider them as exact by adding “multiWordsSynonym” in the array.
The synonyms dictionary also contains alternative corrections that are different semantically and should be considered as one or two typos. The spelling can be very far from the original words and so won’t be cached by the typo detection, so you can define them manually. For the moment this feature is limited to single-word expressions.
Implementation details matter!
The configuration of synonyms is a key aspect of the search relevance and should be configured in most use cases. We have seen in this post that there are a lot of implementation details in the way synonyms are handled that have a direct consequence on the user experience or the ranking.
As with most of the features we introduce in the engine, we have spent a lot of time designing synonyms and how they should behave. This is why we introduced their support progressively: we started with support of single-word synonyms in May 2014, followed by multi-word synonyms in April 2015 and a dedicated API to handle synonyms in June 2016.
We took the time to think about these implementation details and to our knowledge we are the engine that goes the deepest in terms of supporting as-you-type synonyms and multi-word synonym positions to have a perfectly identical ranking. We still have improvements to the way we handle the synonyms in our roadmap – like the hybrid indexing of multi-word synonyms to improve performance.
If you have any other ideas of improvements, we would be very interested to discuss them with you!
We recommend to read the other posts of this series:
















%20(2).svg)










