On March 31st, we announced our CSS API Client, that replicated a search engine with only CSS. While it was only a joke in the spirit of April Fool’s, it was a lot of fun to make, and also a lot of fun to see it in the wild.
I’ve always been fascinated by how much could be done using only CSS (from flags to FPS games). When I started building the demo, I never imagined that I could build such a full-fledge search experience with CSS. The final demo has some huge drawbacks that make it unusable in production (the massive filesize of the generated CSS being the main one), but it still has some nice features that I’d like to shed some light on in this blogpost.
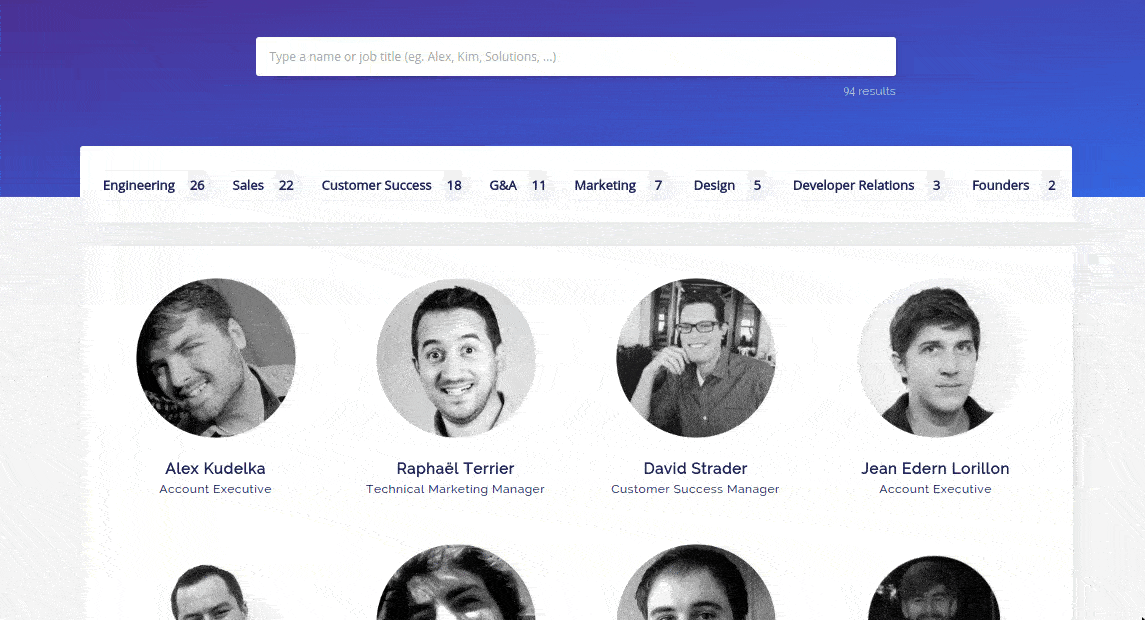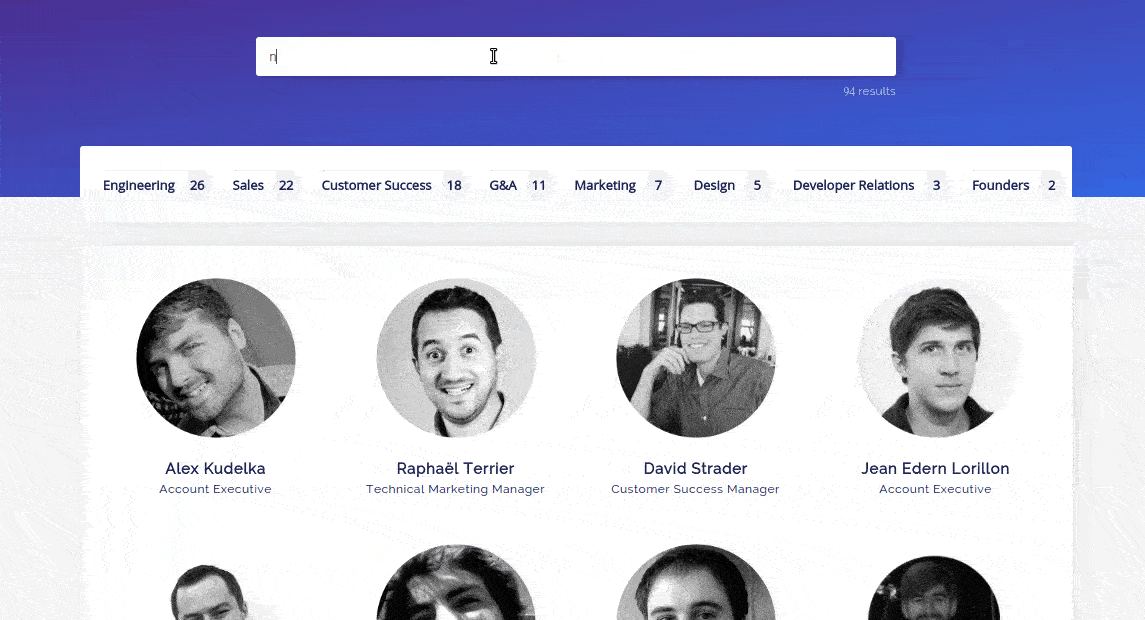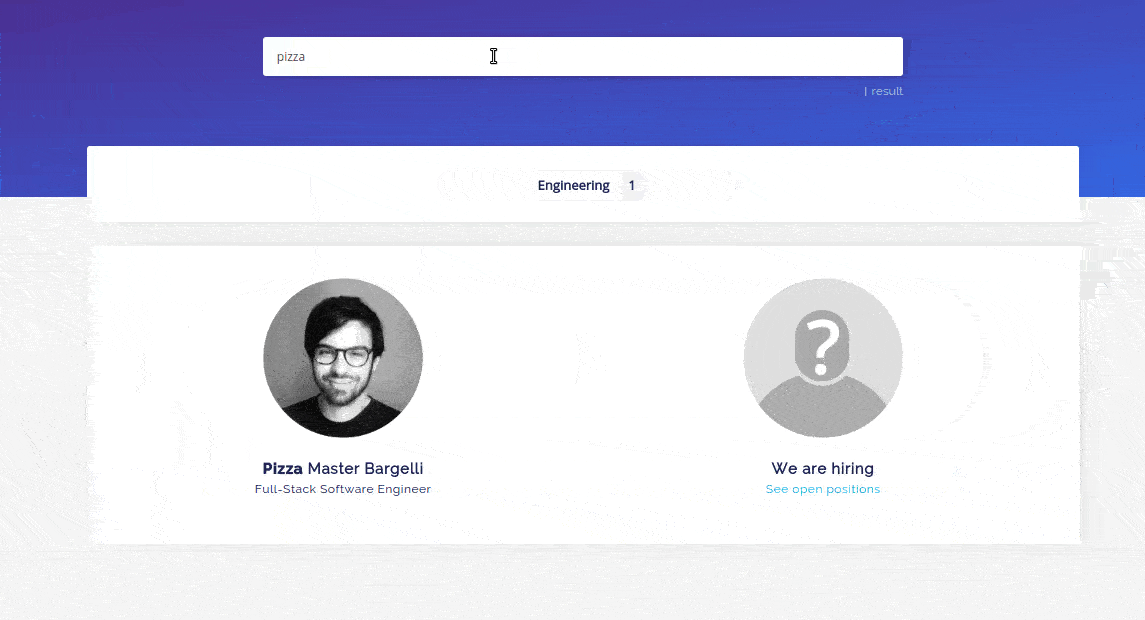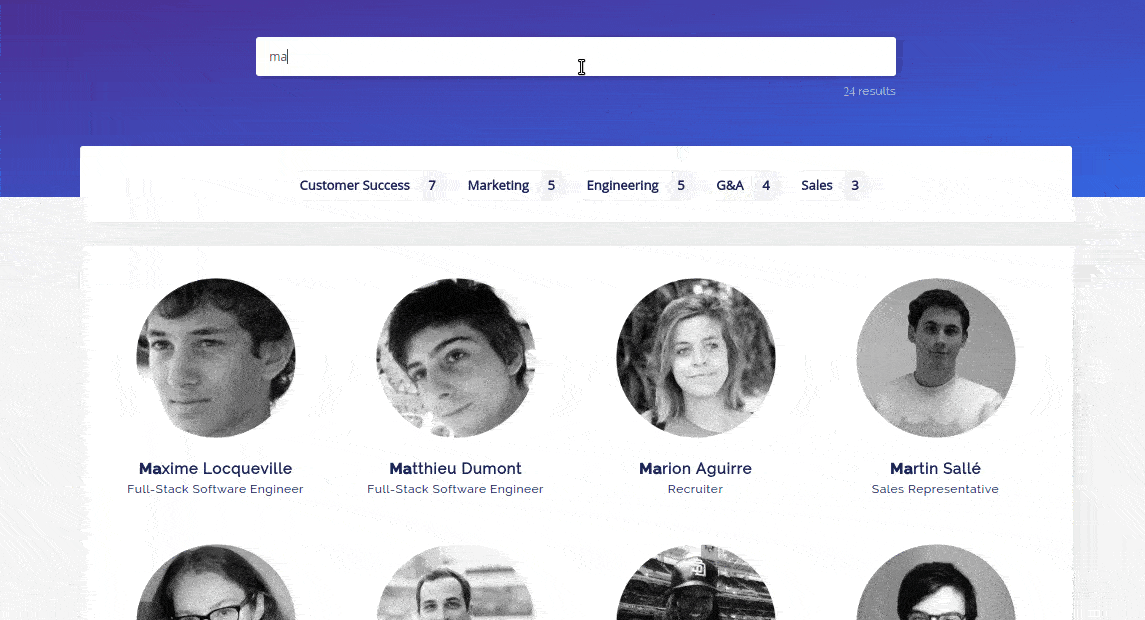
The power of selectors
By design, CSS does not have some of the features we expect from programming languages. It has no conditions, no loops, no functions, no regular expressions… Instead, it has selectors that can target elements in an HTML document and apply styling to them.
Ultimately, targeting elements is one of the greatest strengths of CSS, because it can select elements through a combination of tag names, classes, ids, and attributes. With the sibling selectors (+, > and ~), you can even go crazier in what you can target – this is a big part of how I manipulate CSS for creative CSS projects.
The search bar
When it comes to searching, the first thing that comes to mind is the search bar. This is the ubiquitous element where you input your text, and results gets displayed. In HTML, a search bar is nothing more than an input. It can thus be targeted by CSS.
An input element also has a value attribute. It means I can write a selector that will only match the input when it has a specific value:
<input type="text" value="Tim" />
input[value='Tim'] { background: green; }
When the value of the input is equal to “Tim”, I can change the background of the input to green. This might not seem much, but this is the cornerstone on which the whole CSS API Client is built. It lets me change the styling of elements based on the value of the input.
We’ll see how this will be used, but first I need to talk a bit about JavaScript.
JavaScript: the necessary evil
I know I said this CSS API Client didn’t need any JavaScript, but that wasn’t entirely true. I still need a tiny JavaScript statement for this to work.
When you use an attribute selector in CSS, it uses the value of the attribute that is set in the HTML, at page load. And when you type something in an input, it only updates the “virtual” value of the input (the one you can read with JavaScript), not the one in the HTML. It means that by default, CSS does not catch changes in the value of an input.
As the whole demo is based on that fact, that’s not very convenient.
That’s why I need JavaScript. I want our value attribute to be updated whenever something is typed in the input. This is mandatory to get this as-you-type feeling of results instantly displayed.
<input type="text" oninput="this.setAttribute('value', this.value)">
This simple JavaScript statement can be read as: “Whenever the value changes, set the value equal to the value”. It might seem obvious but is actually needed to pass the correct value from the JavaScript world to the CSS world.
Now that I’ve taken care of that, let’s see how to display the results.
Displaying results
At that point, I can apply some styling to the input based on its current value. It’s a good start, but what I really want is to display results based on what is typed in the input.
Using the + sibling selector, I can target the div that is just following the input in the markup. And by using the :before pseudo-selector along with the content: declaration, I can add some generated content to it.
<input type="text" oninput="this.setAttribute('value', this.value)">
<div></div>
input[value="Tim"] + div:before { content: "Tim Carry" }
input[value="Josh"] + div:before { content: "Josh Dzielak" }
input[value="Vincent"] + div:before { content: "Vincent Voyer" }
Whenever I type Tim, Josh or Vincent, the next div will be populated with the full name.
Prefix search
That works well. but a good search engine shouldn’t have to make you type the full keyword before displaying results. I should see “Tim Carry” as a result as soon as I type “Ti”, or even just “T”.
That’s when the major mental shift occurs:
- As a user, when I am searching, I want the answer to the question: What results will I have if I type “Tim”?.
- But here, as a builder, the question becomes: What should I type to have “Tim Carry” as a result?.
In this example, the answer would be “T”, “Ti”, “Tim”, but also “C”, “Ca”, “Car”, “Carr” and “Carry” if I want to search in both first name and last name. Those variations are called n-grams, which means all the strings that would match a specific record.
Not wanting to do this task by hand, I wrote a Ruby script that generates the n-grams for any word, and outputs the CSS selectors to a new file.
Displaying several results
Now that I had it automated, I started feeding my script with the list of all Algolia employees, to see how it performed. That’s when I realized that displaying only one result was too limiting.
For example, we have 5 people named “Alex” in the company (at some point, 20% of the company was actually named Alex), so I wanted to display all of them when searching for “Alex”, not only the first one.
I changed the HTML markup and instead of having only one div for the result, I created as many divs as the number of employees. I gave each div a unique incremental id (to select them more easily), and pre-filled each of them with the full name using the same :before and content trick.
Those divs were all hidden by default, and only made visible when the value of the input was matching them.
<input type="text" oninput="this.setAttribute('value', this.value)">
<section>
<div id="h0"></div>
<div id="h1"></div>
[...]
<div id="h89"></div>
<div id="h90"></div>
</section>
/* Hide all results */
section div { display: none; }
/* Pre-fill them with the full name, but keep them hidden */
#h4:before { content: "Alexandre Collin" }
#h8:before { content: "Alexandre Stanislawski" }
#h15:before { content: "Alex Kudelka " }
#h16:before { content: "Alexandre Meunier" }
/* Display them only when the value matches */
input[value='Alex'] ~ section #h4 { display: block; }
input[value='Alex'] ~ section #h8 { display: block; }
input[value='Alex'] ~ section #h15 { display: block; }
input[value='Alex'] ~ section #h16 { display: block; }
/* Consider the empty query as matching anything, and display everything*/
input[value=''] ~ section div { display: block; }
Styling
Now that I had the full data-set to play with, I decided to give it a bit more styling, to make it look like the actual “About Us” page we have on the website. Because I’m only using one div per result, I had to resort to a few more CSS tricks.
I added a picture for each of us as a background image. I used Cloudinary to make all images round, resized and grayscale. I added a fun fact on hover, using the :after pseudo element and generated content.
To display both the name and job title, I used the special character \A to add a new line in the generated content. I also added white-space: pre so both lines were actually displayed separately. Then, using :first-line I was able to style each line differently.
Edge cases
By playing with an actual dataset, I could start to see some edge-cases that I didn’t expect at first.
The first one was handling case sensitivity. I wanted both “Tim” and “tim” to match the same results. Fortunately, CSS handles that directly without needing me to generate more n-grams. input[value='tim' i] will match “tim” in a case insensitive way. This works on all major browsers except Edge, unfortunately.
All the other challenges had to do with my co-worker, Rémy-Christophe Schermesser. Rémy-Christophe has a very interesting name when it comes to edge-cases.
The first is that his first name is actually composed of two names and I wanted to be able to find him either with “Rémy” or “Christophe”. In addition to splitting the name on spaces (to identify first name and last name), I also had to split them on dashes.
The second part was that his name actually uses an accented character (é), and I wanted to be able to find him either by typing “Remy” or “Rémy”. I had to normalize the names, and generate n-grams for the normalized version as well.
Finally, his last name, “Schermesser”, is difficult to spell correctly on the first try. I wanted people to be able to find him even if they wrote “Shermesser” (without a “c”), or “Schermeser” (with only one “s”). Typos are very common in search, especially on mobile (thanks to the fat-finger effect), so a good search engine should auto-fix them as much as it could.
To handle the typos for this specific word, I had to generate 40 more n-grams, one for each variation of the word with one letter removed (except for the first and last one). “Ser”, “Sherm”, “Scermes”, “Schrmesser”, etc were all valid new n-grams to find “Schermesser”.
The funniest thing in this story is that, even in the office, almost no-one ever calls him Rémy-Christophe. Everyone calls him “RCS”, and I wanted to replicate this in the engine, through the use of synonyms. Adding a synonym is nothing more than manually adding a new set of n-grams that should match a specific result. In my case, “r”, “rc” and “rcs” were now also valid keywords to find Rémy-Christophe.
Highlighting
At that point, I could search for people either with their first name or last name, including typos, or through synonyms. I decided to also add finding them through their job title. This adds a lot of possibilities, and sometimes it was not obvious why a specific result was displayed.
A good search engine should never let the user wonder why a result is displayed. It must be clear instantly why a result is relevant, and that’s where highlighting comes into play.
The Algolia API handles highlighting by wrapping matching text with the <em> tag. But because I’m using generated content, I cannot add HTML into it, so I had to find another way.
The trick I used was to generate a custom font that is a merge of Raleway Regular and Raleway Bold. I kept the regular font as a basis, but added all the bold characters into the private UTF-8 space. To highlight a word, I replace its letters with their bolded version. CSS lets you use specific UTF-8 characters by using the \eXXX syntax.
input[value='alex' i] ~ section #h4:before { content: '\e641 \e66c \e665 \e678 andre Collin' }

Ordering results
Another really important part of a search engine is that the most relevant results should be displayed first. My current setup wasn’t taking relevance into account at all when displaying results.
This was obvious when searching for “Co”. I had Nicolas and Julien, both Co-founders, displayed before ry Dobson. This was not what I wanted. Cory should have been the first result because the match was in his first name and that was more important.
The Algolia engine handles this by sorting results through a tie-breaking algorithm. We define a list of criterias, and we check each result against those criterias to sort them into buckets. I applied the same logic in my script; my first criterion was that a match in the name was more important than a match in the job title. The sorting should then create two buckets, one for a match in the name, another for a match in the job title.
If there were several results in a specific bucket, it would apply the second criterion to this bucket to further split the results in more buckets.
My second criterion was the position of the match. A match in the first word was more important than a match in the last word. If it would still have ties, it would then sort by the last criterion, the custom ranking. Here I decided that results at that point should be displayed by order of arrival in the company.
You can see it in action with the query “St” for example:

- We have a first bucket with the match on the name, and a second with match in the job title (Full-Stack Software Engineer)
- The first bucket is then split into two more buckets, a match in the first name (Steven Merlino), or a match in the last name (Alexandre Stanislawski, David Strader)
- For each bucket with more than one item, results are ordered by arrival date in the company (Alexandre joined before David, Vincent joined before Maxime, etc)
Now that I know in which order items should be displayed, how do I do that in CSS? This one was actually much easier than anticipated. As soon as you start using flexbox-based display, you can apply an order: to any element to change its position in the display.
input[value='st' i] ~ section #h4 { order: 2 }
input[value='st' i] ~ section #h8 { order: 3 }
input[value='st' i] ~ section #h15 { order: 4 }
input[value='st' i] ~ section #h16 { order: 1 }
Faceting
The last feature to add was the filtering (or faceting, as we call it in the search industry). Faceting is extremely important when the number of results you get is very large, and thus hard to comprehend. It is important to let your users filter it down.
I added a way for users to filter results by team. I used most of the same tricks (generated content, flexbox ordering, etc) that I already used on results. The one thing that is important here is that the facets are actually label elements, each linked to an invisible radio button.
In HTML, you can link a <label for="foo"> with an <input id="foo" type="radio">. Whenever you click on the label, the radio button will get selected, wherever it is in the page. I used that to my advantage, by linking each <label> to a different radio button that I put in the markup right before the main search bar.
Using the :checked pseudo-element and the adjacent sibling selector, it let me create a “global state” to my page, based on which radio is currently checked.
Filtering is applied here by hiding all the results that do not match the selected facet. If I select the team “Engineering”, then I need to hide all results that are not in the “Engineering” team.
<!-- Invisible radio buttons -->
<input type="radio" name="facets" id="f1">
<input type="radio" name="facets" id="f2">
<!-- Main searchbar -->
<input type="text" onchange="this.setAttribute('value', this.value)">
<!-- Facets. Content is set through pseudo-elements -->
<aside>
<label for="f1"></label>
<label for="f2"></label>
</aside>
<!-- Results -->
<section>
<div id="h0"></div>
<div id="h1"></div>
[...]
<div id="h89"></div>
<div id="h90"></div>
</section>
/* When I check the first facet, I hide all results that are not part of this facet */
#f1:checked ~ section #h2 { display: none !important; }
#f1:checked ~ section #h3 { display: none !important; }
Performance
The generated filesize can get huge quickly, as I need to create new rules for each new n-gram. I used one-letter ids as much as I could as it both reduces the filesize, and makes the browser parsing of the CSS much faster. I then minified the file by grouping selectors sharing the same rules together. Still, the final file is 4Mb.
I’ve also removed the !important keyword (taking too many characters) by artificially boosting the specificity of my rules instead (#f1[id] is more specific than #f1 for example but will still target exactly the same elements).
Conclusion
By splitting a complex problem into small chunks, and using the strength of the language that was at my disposal, I managed to build the illusion of a search engine in CSS, which made for a great basis of some April Fool’s fun. While the demo could never be applied in production – the file size is too big, the results cannot be selected nor clicked and it lacks many features a real search engine should give you – it was a great opportunity for me to stretch what’s possible with CSS, and for us at Algolia to bring a smile to our community and a few new faces who discovered us from our prank. You can have a look at the source code on GitHub.
Search is all about speed, relevance and UX, and we’ve only scratched the surface of those three pillars here because we were limited by the CSS language; however, we’re glad the prank & demo sparked some great conversations in the CSS community and we look forward to discussing more with you.















%20(2).svg)










