How do you measure the success of a new feature? How do you test the impact? There are different ways of doing this including feature flags. Many people have used A/B testing solutions, too, like Optimizely or other third party systems to test the impact of their features.
When it comes to Algolia, our customers want to understand how a new feature might impact conversion and click-through rates, or boost revenue. Within our product dashboard is an A/B testing feature that customers can use to run their tests. Customers will start an A/B test with a hypothesis — perhaps some change like dynamic reranking or AI search might increase the click-through rate or conversion rate over and above their control.
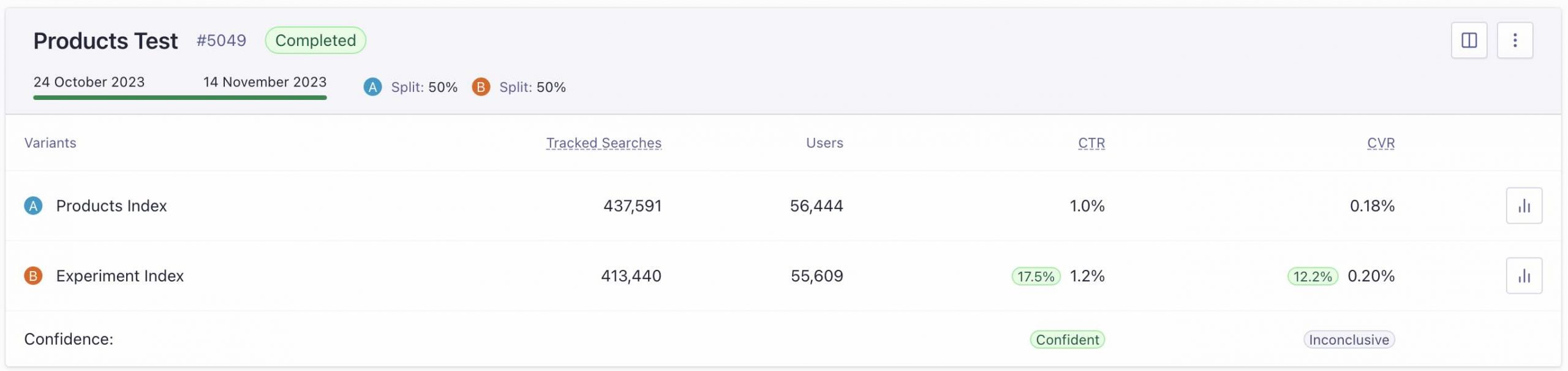
The dashboard shows click through rate (CTR) and conversion rate (CVR). As the test progresses, we measure things like uplift and significance, too. In this example below, we’re measuring results from a personalization test between two different variants. These tests are live on a site, and clicks and conversions can sometimes be tainted with inaccurate data.
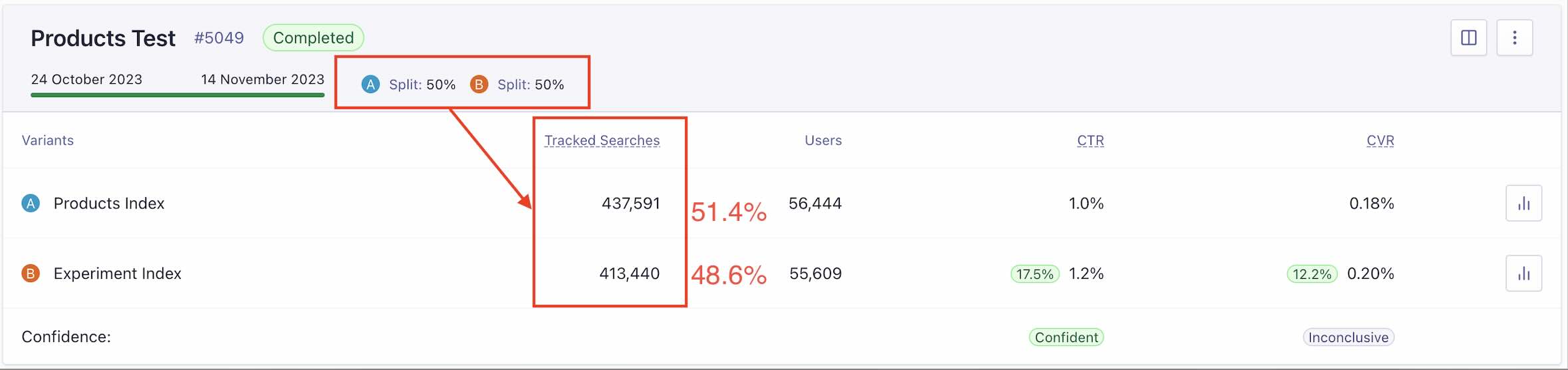
One thing you may notice on this screen above is that there is a difference in Tracked Searches. Quite a big difference. While a 50/50 traffic split is what the customer has configured, the distribution of them is actually quite large. It’s an almost 3% difference which equates to 20,000 more tracked searches in one test versus another. Ideally it should be a little bit better than this, a little bit closer to a true 50/50 split.
Why the difference? Bots are basically the answer. Unless a customer is explicitly disabling click analytics, you could get these bots doing thousands and thousands of searches. It throws off click-through and conversion statistics, which in turn affects results. Of course, it’s not just a nuisance; it has real ramifications for our customers who are attempting to optimize their businesses. This activity interferes with getting clean results.
We wanted to find a way to remove these outliers automatically to give customers more accurate results. In this blog, I will explain how we set out to tackle this problem.
By the numbers
Here’s a simple example. Let’s say you have one A/B test variant with 10,000 searches and 1500 conversions, it’s a 15% conversion rate. Just a simple division. A second variant has 10,900 searches with 1600 conversions, or a 14.6% conversion rate.

If the second variant was caused by bot traffic, you get a bad uplift. It went from 15% conversion to 14.6%. Our customers will see this as a bad trend. If we fix the problem, we might discover that 1000 searches were false positives. When we remove those, suddenly the real results are able to come through.

In fact, the test had a great outcome with a 16% conversion rate. This is a very skewed example, but it makes the point. It can also go in the other direction: sometimes when we remove bot traffic, it could lead to a worse uplift, but it’s a more honest approximation. It’s an objectively more accurate uplift.
What is an outlier?

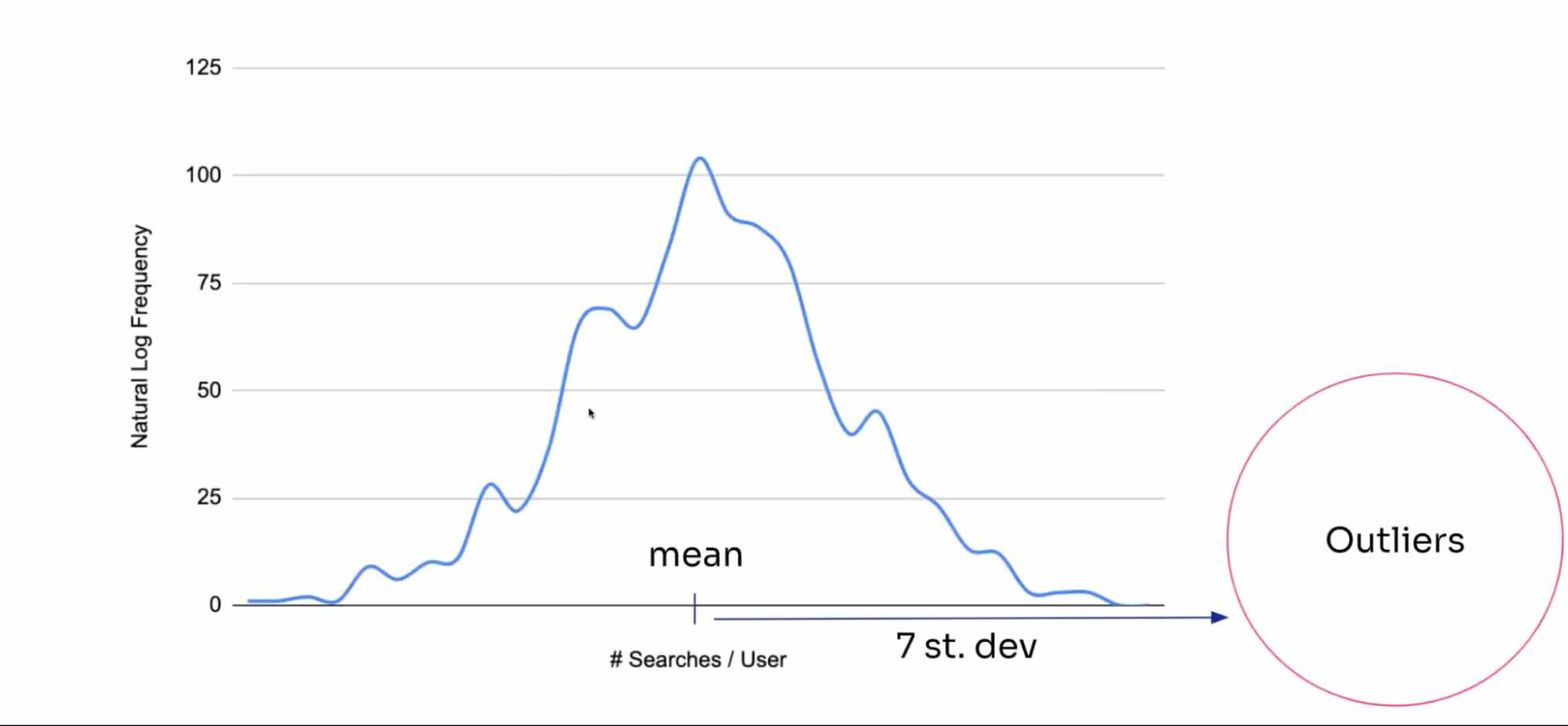
With the new setup, we were able to more quickly and accurately label data as an outlier. So what is an outlier? If you look at a normal log distribution for something that might look like the graph above. This graph is hypothetical — in most sites, the data is quite different and includes a much deeper longtail. However, for this hypothetical example, you’ll see that most people will do between two and five searches on a website. They’re not going to be doing thousands of searches. As you count searches across thousands of sessions, you’ll find outliers on the far right — people who are doing a really high number of searches. And so the question is: how do you quantify that? Where do you set the cutoff point between legit searches and what appear to be fake data?
At Algolia, we’ve set a threshold of at least 100 searches, and then they need to have greater than seven standard deviations away from the mean number of searches per user, which is a ridiculous number. In other words, there has to be a crazy number of searches outside of the mean for an application in order to qualify for this.
The flat 100 searches is to exclude these very unique data sets where you have one single search being 99% of your searches. It helps ensure that people who do 2 or 3 searches are included, but anybody that’s doing greater than 99.99999 is a good candidate for being labeled an outlier.
.jpg)
The graph above is called a log-normal distribution. To get the mean and standard deviation, we take the natural log of each of this data set which gives us something that looks more like a normal distribution’s bell curve. At this point, we can then take normal mean and standard deviation. We transform our data into something like this:
We can then classify all those users with a threshold and label them as outliers. To develop this method, one of our engineers, Hugo Rybinski, investigated different algorithms for detecting outliers. He looked at things like isolation forests and generating data, and decided that it’s much easier and faster to simply label people with too many searches as outliers. Another teammate, Raymond Rutjes, also did a lot of the groundwork to help us arrive at this solution today. He had started implementing outlier removal. So, a big shout out to both of them!
A/B testing set up
To exclude outliers, we added a global configuration to each test that gets created whereby outliers are excluded by default. We aggregate all of the data and exclude outliers from calculations.
And the result looks something like this:
.jpg)
.jpg)
We can return results to customers with the excluded outliers. In the example above, it’s an A/B test with a 75/25 split. One cohort had 29,000 tracked searches removed, which represented 26 outlier users. The more accurate data helps customers to be able to interpret the A/B test and make informed decisions and hopefully increases their trust in the data.
What’s next for A/B testing
I hope you enjoyed this peek inside Algolia engineering and how we have approached this problem. A/B testing is a core feature of the product that enables customers to improve the search algorithm and take advantage of different features, so have continue to focus on developing improvements for it. In fact, we have even more coming soon such as
- Support for additional feature-specific A/B testing.
- Syntax tree representation of filters — dynamic query structuring to operate on certain types of searches.
- Sample size estimates to help customers know exactly how long to run their tests for.
… and way more! You can learn more about running A/B testing in our documentation.
















%20(2).svg)










